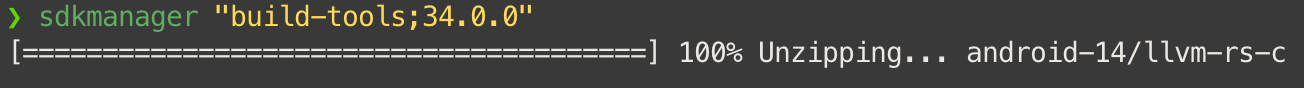repo: https://github.com/wistbean/learn_python3_spider http://www.spiderbuf.cn/ , https://scrape.center/
Packet Sniffing / Capturing HTTP 请求方式:GET, POST , PUT, DELETE, HEAD, OPTIONS, TRACE
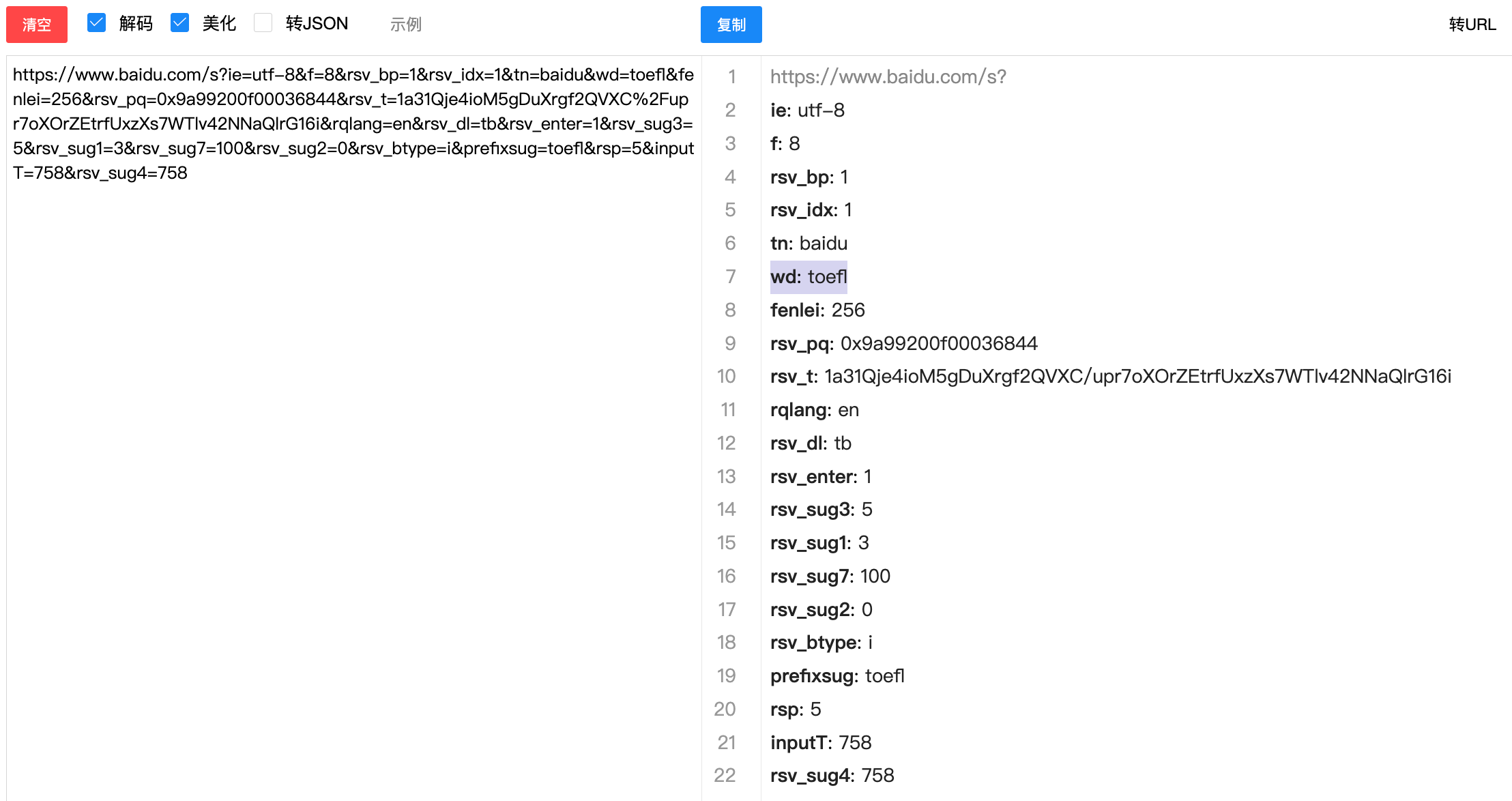
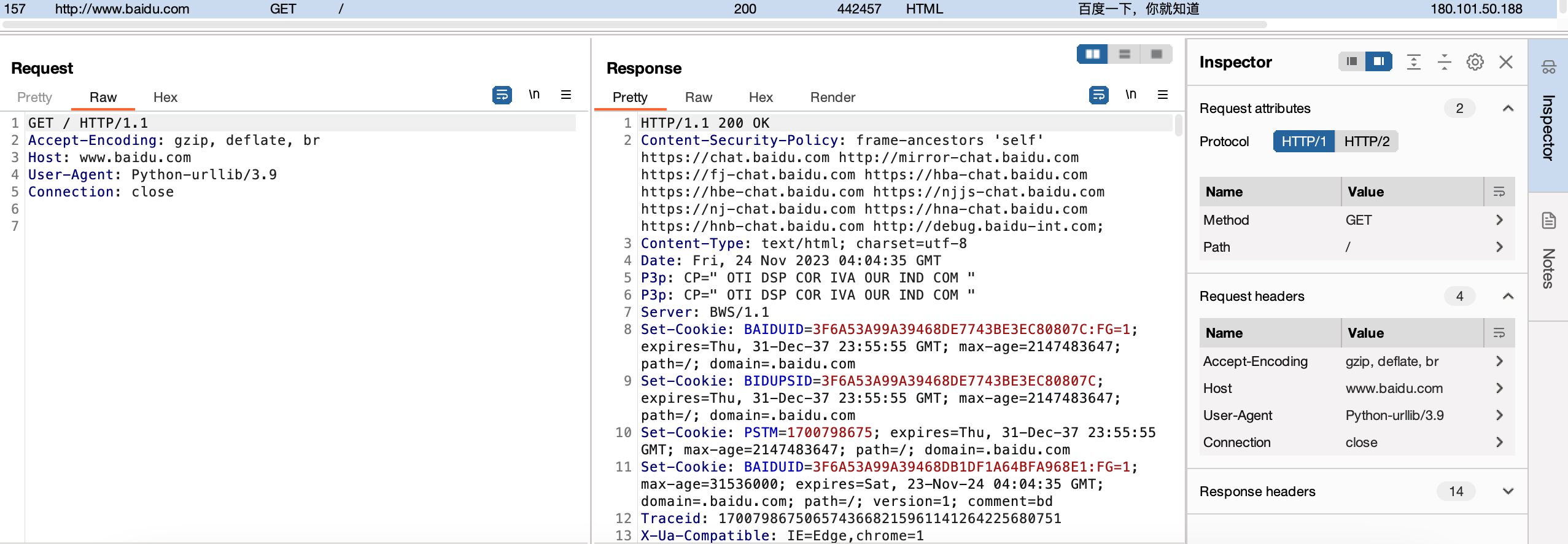
GET Request 在百度搜索框输入“toefl”,点击“百度一下”,获得的url如下,服务器https://www.baidu.com/s通过?进行GET请求,GET请求以键值对方式传递参数,经url格式化后如下。
POST Request 在百度搜索页面中点击“登陆”,输入”testusername”作为用户名,”testpassword”作为密码,点击“登陆”,在控制台中的 Network 选项中可以看到名为 api/?login 的 request,从 Headers 中可以看出这是一个 post 请求,在 Payload 中可以看出 post 请求以 form 表单方式传递参数。
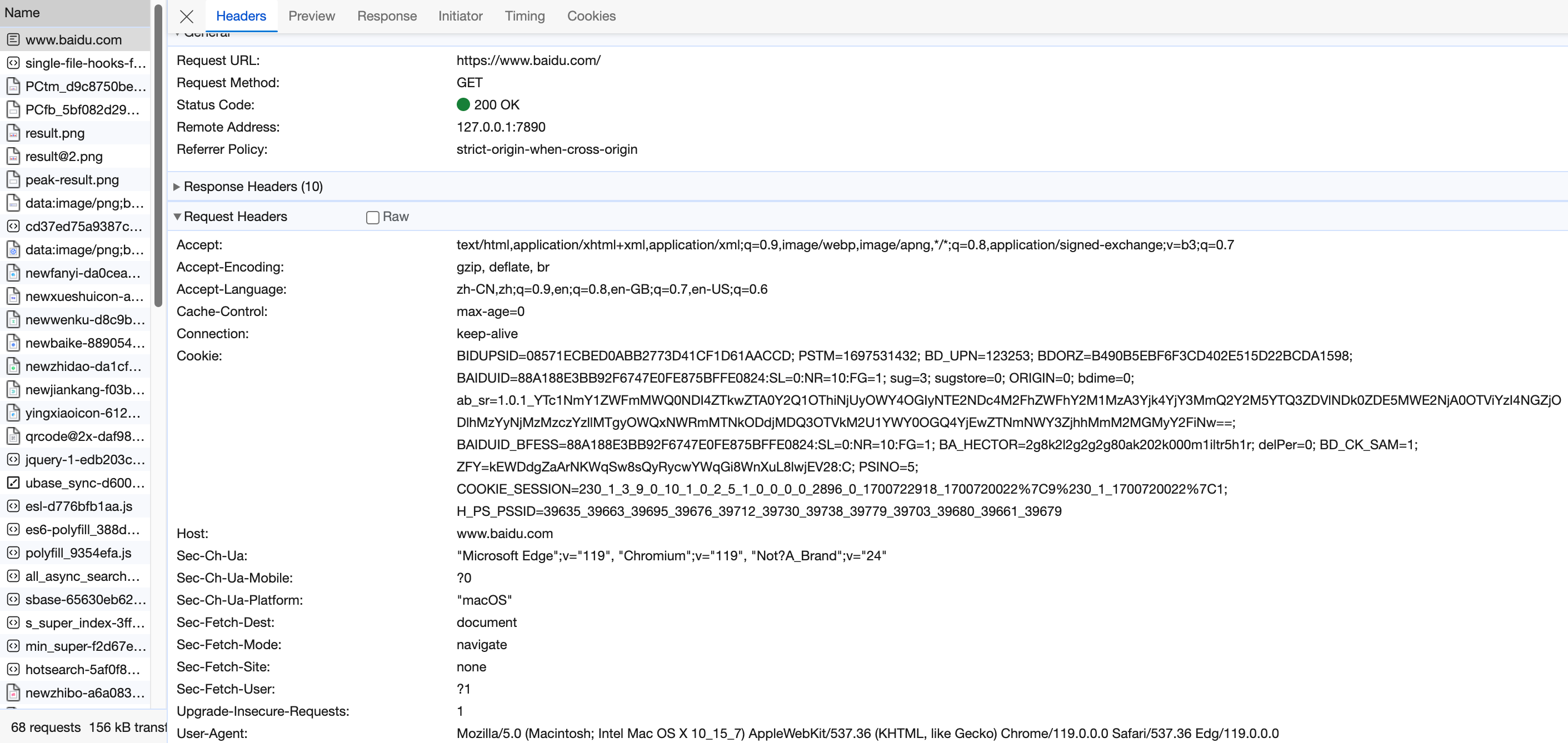
Http Request 除了提交参数外,还会有一些用于定义其自身的信息,如 Accept、Host、Cookie、User-Agent等。其中,Cookie是服务器保存在浏览器(客户端)中的用户信息,用于模拟用户登录状态;User-Agent是用户代理(一般是浏览器)信息,用于模拟正常的浏览器行为而非程序爬虫行为。
事实上,Request 由 Request Line, Request Header 和 Request Body 组成。其中 GET Request 不包含 Request Body。
Response Status Line, Response Header 和 Response Body 共同组成一个 Response。
Status Line 由 Status Code 和 描述组成,如 200 OK 代表成功。
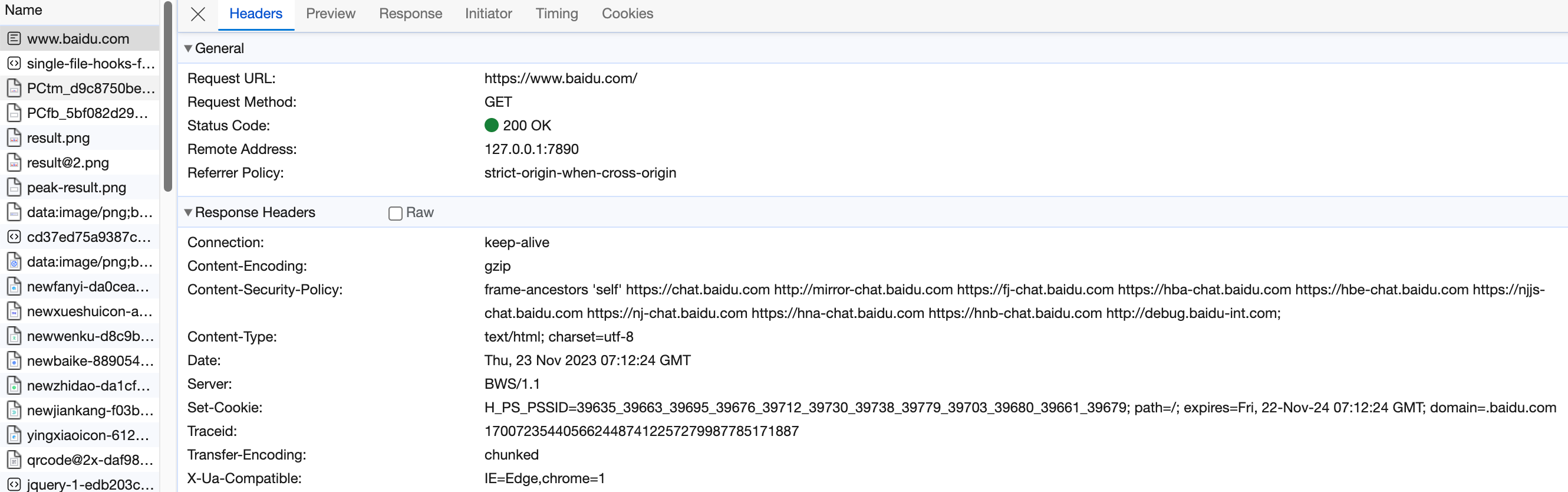
Response Header 包括服务器信息和响应体的信息
Response Body 即为进行 Request 后的网页,可以通过渲染成为可视化的网页。
Capturing Mobile Phone Packets 浏览器自带控制台无法满足更专业的抓包需求,需要使用专业工具,如 Fiddler 或 BurpSuite。
关于 BurpSuite 的下载、安装、破解,见:BurpSuite全平台破解通用-至今可用 - SaberCC Blog (ccalt.cn) Intercepting HTTP traffic with Burp Proxy - PortSwigger
接下来记录移动设备抓包,以 iPhone 为例。
先跳过,iPhone和MacBook在校园网下不在同一网段,mac没法开热点。
Urllib Library urllib 是 python 的内建库,包括 4 个模块:request, error, parse, robotparser
模块的功能都是顾名思义的,不用说了,下面进行 request 模块的使用。
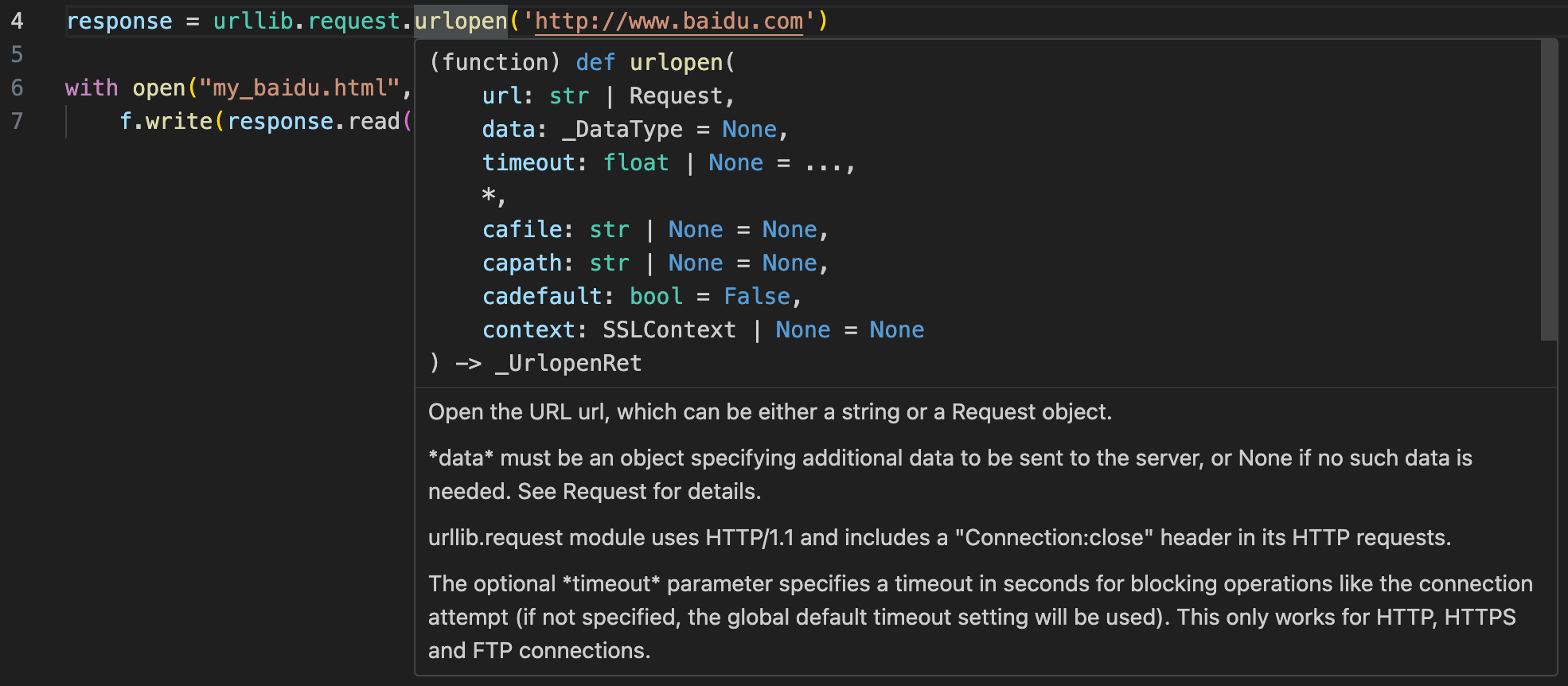
1 2 3 4 5 6 7 from urllib import requestresponse = request.urlopen('http://www.baidu.com' ) with open ("my_baidu.html" , 'w' ) as f: f.write(response.read().decode("utf-8" ))
使用 urlopen 方法即可对 url 发起 GET Request,其 Response Body 会作为方法的返回值。
urlopen 方法的参数说明,主要使用 url, data, timeout 参数。data 参数用于传递 post 请求的参数,若其为空则 urlopen 为 GET Request,若不为空则为 POST Request。
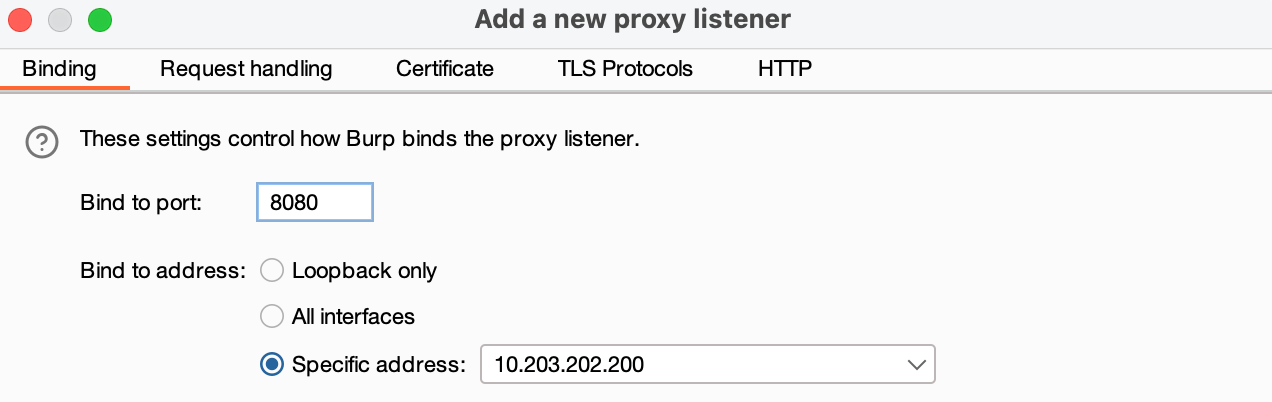
此时,在终端中将代理临时设置为 burpsuite 可捕获的代理,即可在 burpsuite 中看到 urllib 库发送的 GET Request。
临时代理设置命令:export http_proxy='http://127.0.0.1:8080'
可以看到 Request Header 中的 User-Agent 直接显示了 Python-urllib/3.9
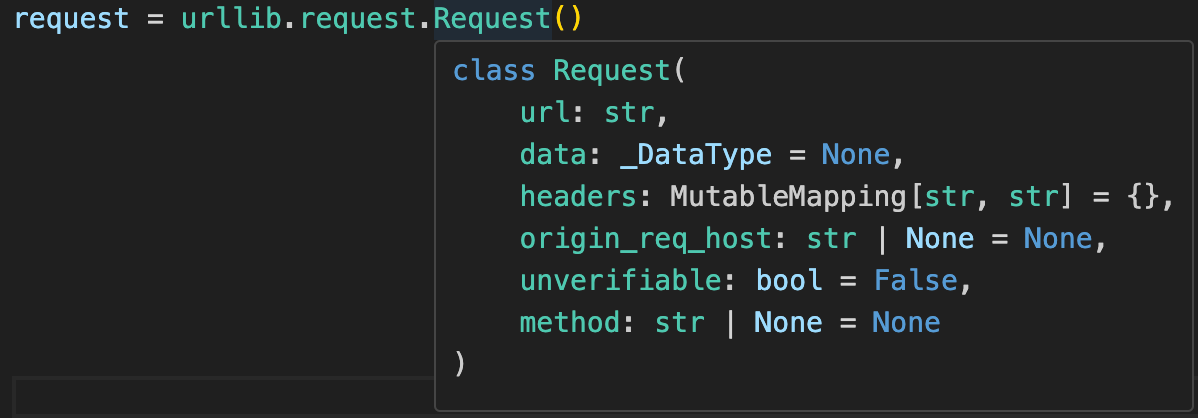
为了欺骗服务器该 Request 是浏览器发出的正常访问行为,需要使用urllib.Request方法来定义具体的 Requset。
简单查看一下 Requset 方法,发现其除了可以指定 Requset 的 url 和 data 外,还可以指定 header 和 method。
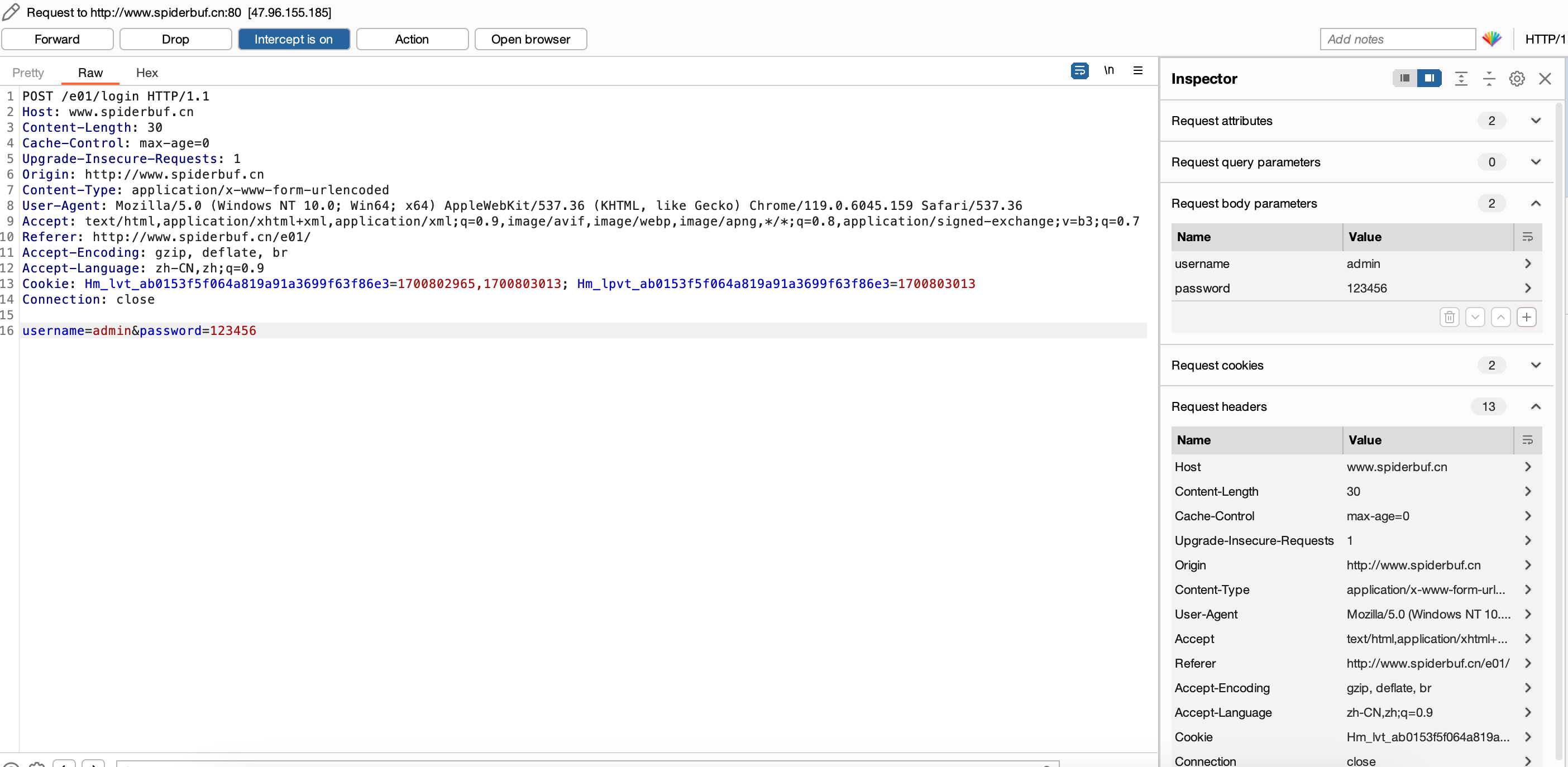
这时可以使用靶场练习,以 Spiderbuf E01 为例。
使用浏览器进入关卡,使用默认账户密码,点击“登陆”,提交 POST Request。Burp 截获到 POST Request,对其进行分析。
发现提交的 payload aka form data 是明文。此外,也获取到了 header 中的正常浏览器信息 User-Agent,我们可以用这些信息来模拟浏览器登录。
根据截获的 request header 和 request body 中的信息及前面 urllib 的简单应用,可以写出以下脚本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from urllib import request, parsecontext = None url = 'http://www.spiderbuf.cn/e01/login' headers = { "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.6045.159 Safari/537.36" } payload = { "username" : "admin" , "password" : "123456" } payload = bytes (parse.urlencode(payload), "utf-8" ) req = request.Request(url, data=payload, headers=headers, method="POST" ) res = request.urlopen(req, context=context) with open ("my_spiderbuf_e01.html" , 'w' ) as f: f.write(res.read().decode("utf-8" ))
运行,得到报错 urllib.error.HTTPError: HTTP Error 307: Temporary Redirect,但这反而说明代码语义正确,因为这个关卡在身份验证通过后就是会重定向到另一个网页,如果想要处理这个 error,就需要用到前面提到的 urllib.error 模块。
Requests Library requests 库基于 urllib 内建库开发,因此比其更强。
示例见 jupyter notebook
Reg ular Exp ression正则表达式语法
转义字符
描述
d
digita,任意数字,$[0, 9]$
D
$\neg$d,任意非数字,$\mathbb{U}-[0, 9]$
w
word,传统可识别字符,$[0, 9]+[a, z]+[A, z]+\{_\}$
W
$\neg$w
n
newline,换行
r
return,回车
t
tab,制表
s
space,所有空白字符
S
$\neg$s
标记字符
描述
^
字符串起始符
$
字符串结束符
.
通配符,匹配一个任意字符(除\n)
[…]
匹配一个标记的字符
... 匹配一个未标记的字符
()
子表达式 / 捕获组
|
或逻辑
{}
数量限定符,{n}代表匹配前面的字符n次,{n,m}代表匹配前面的字符至少n次至多m次,m可为空
*
{0,}
+
{1,}
?
{0,1}
在 python 中使用正则表达式使用 re 库,re.findall 方法类似于 Ctrl+F,re.sub 方法类似于 Ctrl+R。
re.findall
1 2 3 4 5 6 7 8 import recontent = '''I am trying to list some unit conversion: 1m=10dm=100cm=1000mm 1L=10dL=1000mL''' res = re.findall("\d+[a-zA-Z]+" , content) print (res)
1 ['1m', '10dm', '100cm', '1000mm', '1L', '10dL', '1000mL']
re.sub
1 2 3 4 5 6 7 8 import recontent = '''I am trying to list some unit conversion: 1m=10dm=100cm=1000mm 1L=10dL=1000mL''' res = re.sub("=" , " " , content) print (res)
1 2 3 I am trying to list some unit conversion: 1m 10dm 100cm 1000mm 1L 10dL 1000mL
re.complie,将正则表达式及标记保存为正则表达式对象以便复用
1 2 3 4 5 6 7 8 9 import repattern = re.compile ("\d+[a-z]+" , re.I) content = '''I am trying to list some unit conversion: 1m=10dm=100cm=1000mm 1L=10dL=1000mL''' res = re.findall(pattern, content) print (res)
1 ['1m', '10dm', '100cm', '1000mm', '1L', '10dL', '1000mL']
Demo 1: 当当网 Top 500 五星书籍 分析 目标url:http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-1
1. 每页显示 20 本书
2. 页数对应 url 的最后一个参数,可用变量实现翻页
3.
GET Request
Response
4. 所需信息
排名、图片地址、书名、推荐指数(补充分析发现该好评榜所有书籍均为5星)、作者、五星评分次数、价格
Ctrl + F 定位到信息所在标签,<li>标签。找到待过滤的所需信息。这里在 Element 标签下查看。
程序思路
使用 page 变量指定页面
使用 GET Request 进行页面请求
使用 regex 对 HTML Response 进行所需信息过滤
把信息存储到文本文档中(后面可能会学习存储到数据库)
代码实现 !NOTE! 使用这份代码爬到的信息会有错位问题,仅可作为练习用,解释见下章代码实现节。
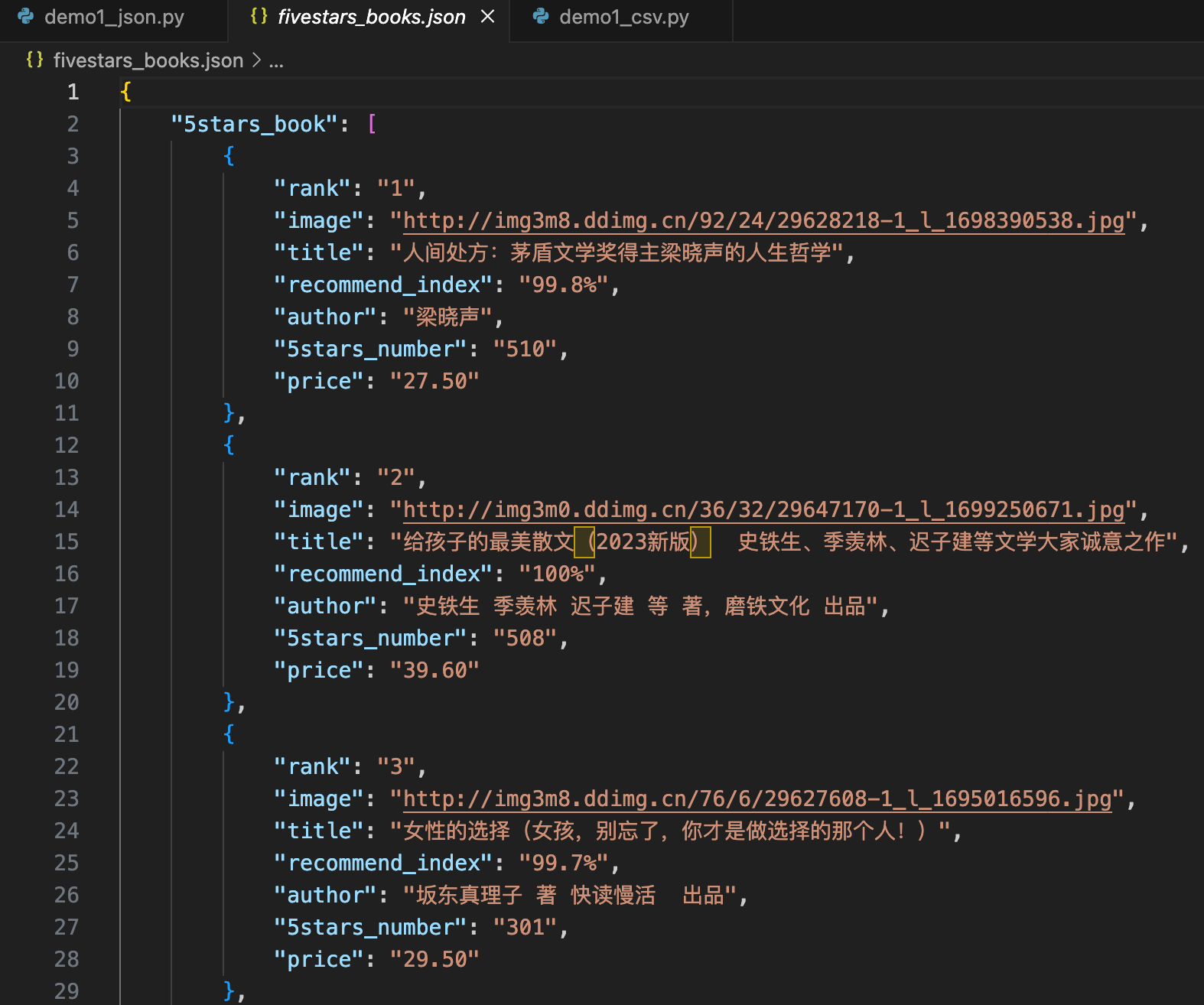
写入到 json 文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 import reimport jsonimport requestsdef request_html (url ): headers = { "Cookie" : "ddscreen=2; ddscreen=2; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; __permanent_id=20231125224536629264140414679707403; ddscreen=2; __visit_id=20231127162657511199966560194631544; __out_refer=; pos_6_start=1701075618952; pos_6_end=1701075619070; __rpm=...1701075804280%7C...1701075808570; __trace_id=20231127170908374355067728566175250" , "User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0" , } try : res = requests.get(url, headers=headers) if res.status_code == 200 : return res.text except : return None def parse_result (html ): ''' <li>.*? <div class="list_num.*?>(.*?)\.</div>.*? <div class="pic">.*?<img src="(.*?)".*? <div class="name">.*?title="(.*?)".*? <div class="star">.*?<span class="tuijian">(.*?)推荐.*? <div class="publisher_info">.*?title="(.*?)".*? <div class="biaosheng">五星评分:<span>(.*?)次.*? <div class="price">.*?<span class="price_n">¥(.*?)</span>.*? </li> ''' pattern = re.compile ('<li>.*?<div class="list_num.*?>(.*?)\.</div>.*? <div class="pic">.*?<img src="(.*?)".*?<div class="name">.*?title="(.*?)".*?<div class="star">.*?<span class="tuijian">(.*?)推荐.*?<div class="publisher_info">.*?title="(.*?)".*?<div class="biaosheng">五星评分:<span>(.*?)次.*?<div class="price">.*?<span class="price_n">¥(.*?)</span>.*?</li>' , re.S) items = re.findall(pattern, html) for item in items: yield { "rank" : item[0 ], "image" : item[1 ], "title" : item[2 ], "recommend_index" : item[3 ], "author" : item[4 ], "5stars_number" : item[5 ], "price" : item[6 ], } def write_item_to_json (item ): with open ("fivestars_books.json" , 'a' ) as f: f.writelines(json.dumps(item, ensure_ascii=False ) + (',\n' if item["rank" ]!="500" else '\n' )) with open ("fivestars_books.json" , 'w' ) as f: f.writelines('{"5stars_book":[\n' ) for page in range (1 , 25 +1 ): url = f"http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-{page} " html = request_html(url) items = parse_result(html) for item in items: write_item_to_json(item) with open ("fivestars_books.json" , 'a' ) as f: f.writelines(']}\n' )
格式化后的 json文件
写入到 csv 文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import reimport csvimport requestsdef request_html (url ): headers = { "Cookie" : "ddscreen=2; ddscreen=2; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; __permanent_id=20231125224536629264140414679707403; ddscreen=2; __visit_id=20231127162657511199966560194631544; __out_refer=; pos_6_start=1701075618952; pos_6_end=1701075619070; __rpm=...1701075804280%7C...1701075808570; __trace_id=20231127170908374355067728566175250" , "User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0" , } try : res = requests.get(url, headers=headers) if res.status_code == 200 : return res.text except : return None def parse_result (html ): ''' <li>.*? <div class="list_num.*?>(.*?)\.</div>.*? <div class="pic">.*?<img src="(.*?)".*? <div class="name">.*?title="(.*?)".*? <div class="star">.*?<span class="tuijian">(.*?)推荐.*? <div class="publisher_info">.*?title="(.*?)".*? <div class="biaosheng">五星评分:<span>(.*?)次.*? <div class="price">.*?<span class="price_n">¥(.*?)</span>.*? </li> ''' pattern = re.compile ('<li>.*?<div class="list_num.*?>(.*?)\.</div>.*? <div class="pic">.*?<img src="(.*?)".*?<div class="name">.*?title="(.*?)".*?<div class="star">.*?<span class="tuijian">(.*?)推荐.*?<div class="publisher_info">.*?title="(.*?)".*?<div class="biaosheng">五星评分:<span>(.*?)次.*?<div class="price">.*?<span class="price_n">¥(.*?)</span>.*?</li>' , re.S) items = re.findall(pattern, html) for item in items: yield item with open ('fivestars_books.csv' , 'w' ) as f: csv_writer = csv.writer(f) csv_writer.writerow(["Rank" , "Image" , "Title" , "Recommend Index" , "Author" , "5 Stars Number" , "Price" ]) for page in range (1 , 25 +1 ): url = f"http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-{page} " html = request_html(url) items = parse_result(html) for item in items: csv_writer.writerow(item)
格式化后的 csv 文件
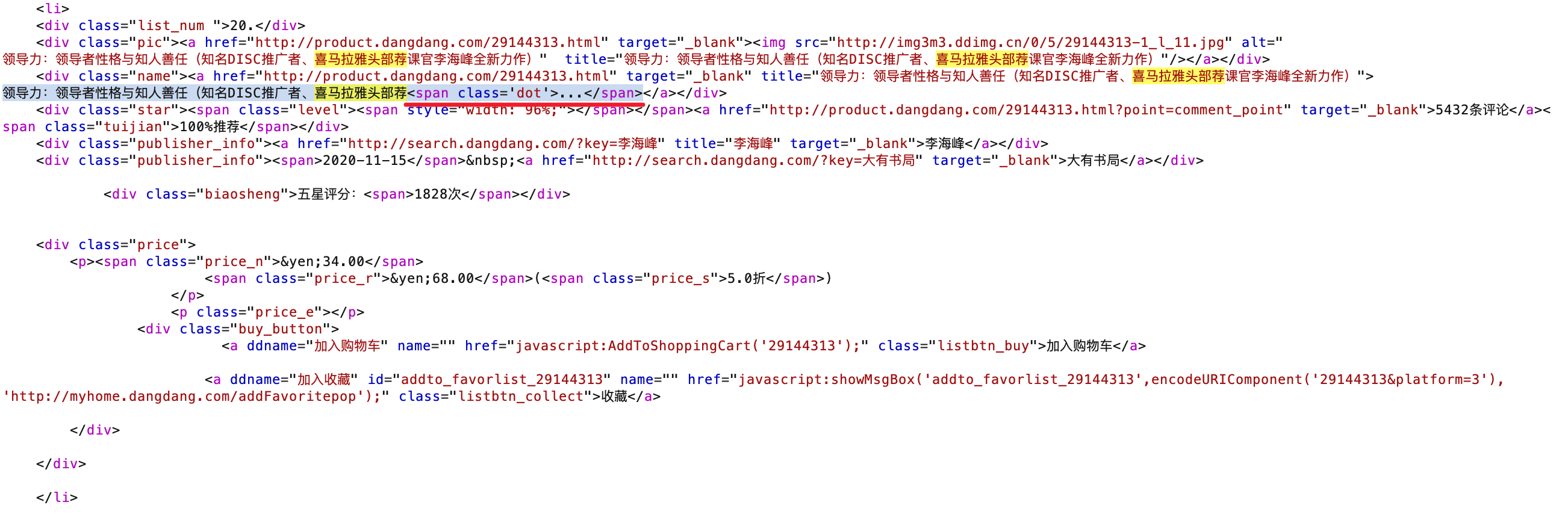
实现细节 挑选所需信息 有时候所需信息会在多个标签出现,这时最好从标签内的属性中捕获文字,不要捕获渲染出来的(显示在屏幕上的)文字,因为尺寸限制,屏幕上的文字可能显示不全,出现领导力:领导者性格与知人善任(知名DISC推广者、喜马拉雅头部荐... 这种情况。
怎么写 regex 可以直接复制渲染某个条目的所有代码,然后将其中不需要的信息(非定位非捕获)更换为任意字符 regex;将其中需要的信息更换为任意字符捕获组 regex。
任意字符:.*?,用于字符串跳过
任意字符捕获组:(.*?),用于捕获定位捕获组内的所有字符
捕获组前后最好都有定位字符串,前字符串最好从共同的标签(<div>)开始,到紧挨着捕获组的字符结束;后字符串从紧贴捕获组的字符开始
前定位字符串
捕获组
后定位字符串
<div class="pic">.*?<img src="(.*?)".*?
<div class="name">.*?title="(.*?)".*?
<div class="star">.*?<span class="tuijian">(.*?)推荐.*?
<div class="publisher_info">.*?title="(.*?)".*?
<div class="biaosheng">五星评分:<span>(.*?)次.*?
<div class="price">.*?<span class="price_n">¥(.*?)</span>.*?
BeautifulSoup Library 既然 regex 并不难写,自然也会有库帮助我们自动提取信息。
方法测试 见ipynb
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 from bs4 import BeautifulSoupimport csvimport requestsdef request_html (url ): headers = { "Cookie" : "ddscreen=2; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; __permanent_id=20231125224536629264140414679707403; __rpm=...1701075804280%7C...1701075808570; __visit_id=20231128081738921251655595867899598; __out_refer=; __trace_id=20231128081738922580451376020939735" , "User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0" , } try : res = requests.get(url, headers=headers) if res.status_code == 200 : return res.text except : return None def parse_result (html ): soup = BeautifulSoup(html, "lxml" ) items = [] for li in soup.select('li' ): rank_elem = li.select_one('.list_num' ) img_elem = li.select_one('.pic img' ) title_elem = li.select_one('.name a' ) recommend_elem = li.select_one('.tuijian' ) author_elem = li.select_one('.publisher_info a' ) stars_elem = li.select_one('.biaosheng span' ) price_elem = li.select_one('.price .price_n' ) if None in [rank_elem, img_elem, title_elem, recommend_elem, author_elem, stars_elem, price_elem]: continue rank = rank_elem.text[:-1 ] image = img_elem['src' ] title = title_elem['title' ] recommend_index = recommend_elem.text author = author_elem.get('title' , 'None' ) stars_number = stars_elem.text price = price_elem.text item = { "Rank" : rank, "Image" : image, "Title" : title, "Recommend Index" : recommend_index, "Author" : author, "5 Stars Number" : stars_number, "Price" : price, } items.append(item) return items with open ("fivestars_books_bs4.csv" , 'w' ) as f: csv_writer = csv.DictWriter(f, fieldnames=["Rank" , "Image" , "Title" , "Recommend Index" , "Author" , "5 Stars Number" , "Price" ]) csv_writer.writeheader() for page in range (1 , 25 +1 ): url = f"http://bang.dangdang.com/books/fivestars/01.00.00.00.00.00-recent30-0-0-1-{page} " html = request_html(url) items = parse_result(html) csv_writer.writerows(items)
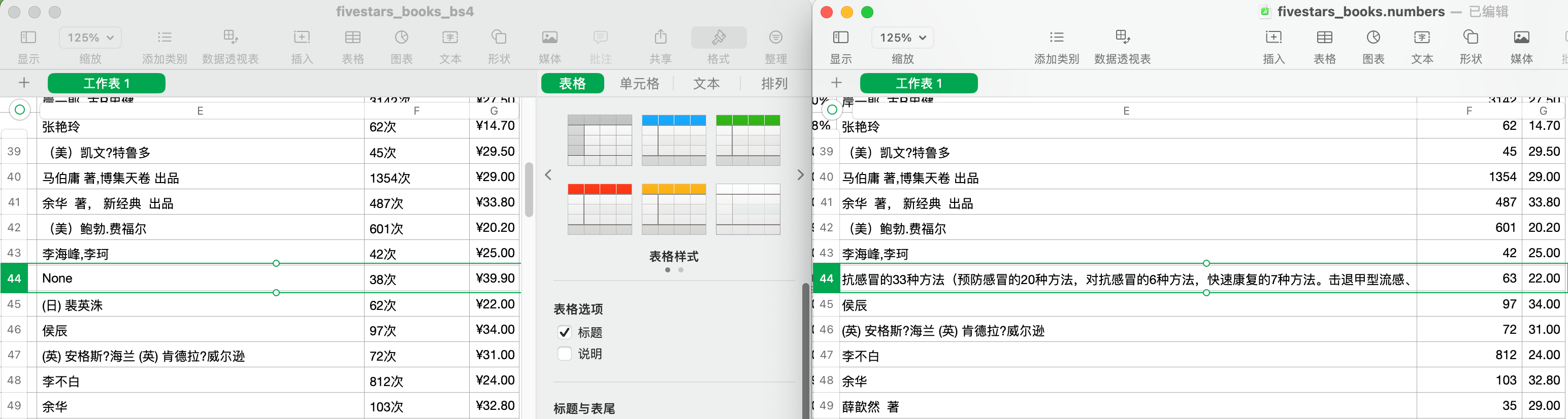
效果比 regex 捕获的信息要好,因为可以判断是否有些信息为空,而不是捕获一些奇怪的东西。
!NOTE! 如果使用 regex ,只要某些信息缺失,就会发生错位,把理应在后面捕获的信息提前捕获,这样爬到的错位信息是完全不对的!
这张图把下一个 item 的 title 当成 author 爬上来了
ps. 两次爬取间(2-3s左右),下一本书还多了1个五星评价。
实现细节 通过 select 解析 HTML 获取信息 先获取在某个元素内(空格)继承了指定类(.)的元素,但这些解析到的元素不一定是渲染书 item 的,只有当所有元素都不为空时才是描述书 item 的,所以要先进行非空检验。
空键处理 如果某些书没有提供作者信息,方括号[] / 重载的__getitem__()是不能从空key获取到value的,会报KeyError,这时要用get()方法提供空键时的返回值。
Demo 2: 豆瓣 Top 250 电影 分析 目标 url: https://movie.douban.com/top250
1. 每页显示 25 个电影
2. 通过 GET Request 参数 ?start=n 指定从第 Top n+1 个电影开始显示
3. 所需信息
电影的排名、宣传图、名称、导演 / 演员、类型、评分、评价人数、简评
程序思路 和 Demo 1 差不多,获取html,解析信息,写入文件。
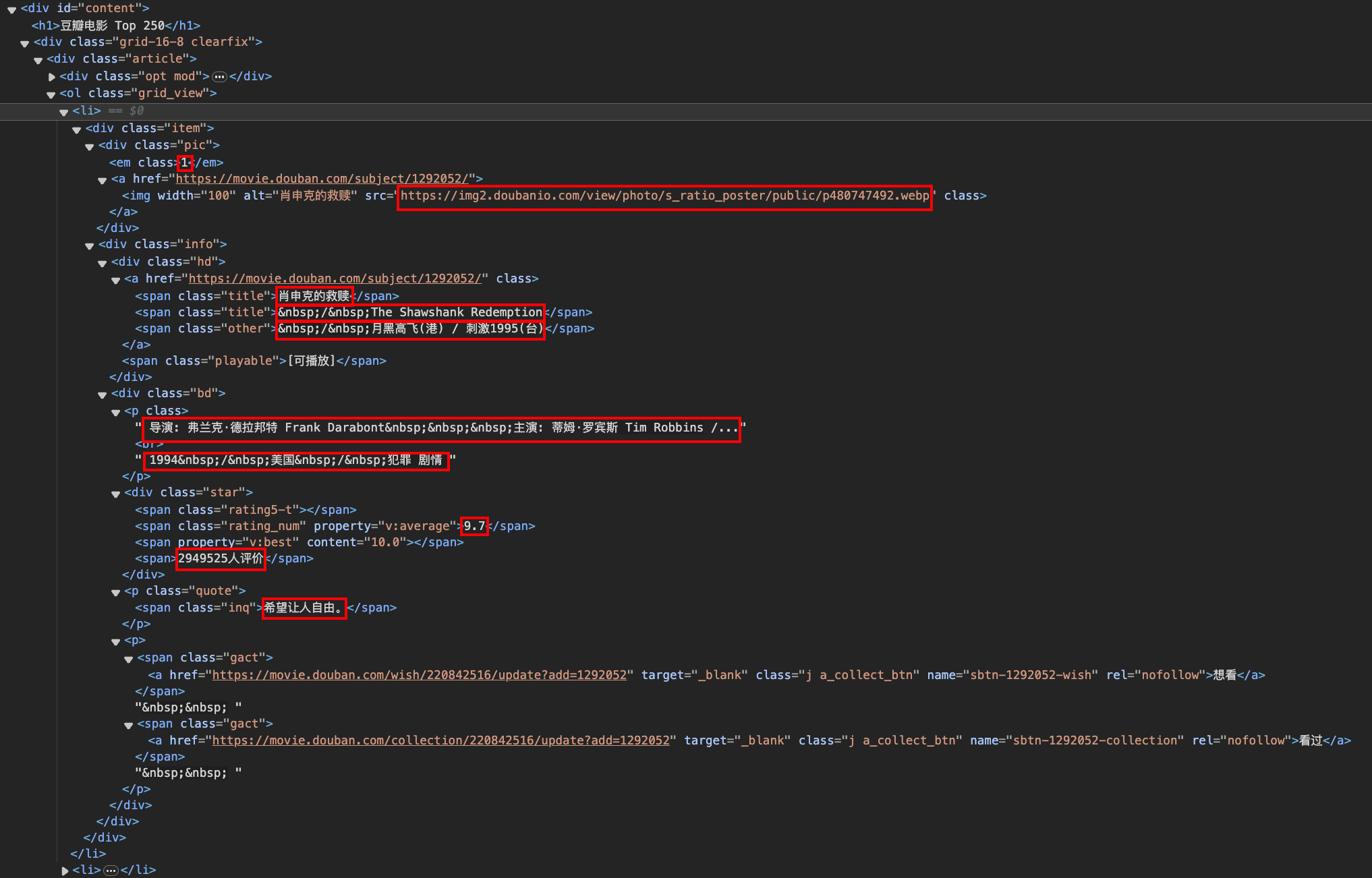
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 from bs4 import BeautifulSoupimport xlwtimport requestsdef request_url (url ): headers = { "Cookie" : 'bid=r5NyipyS844; _pk_id.100001.4cf6=8d2637ab28beb521.1698656720.; dbcl2="220842516:kaSCAN2Yw5c"; ck=u7Tj; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1701170775%2C%22https%3A%2F%2Fopen.weixin.qq.com%2F%22%5D; _pk_ses.100001.4cf6=1; __utma=30149280.1380904537.1698110791.1698656720.1701170775.3; __utmb=30149280.0.10.1701170775; __utmc=30149280; __utmz=30149280.1701170775.3.3.utmcsr=open.weixin.qq.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utma=223695111.603104195.1698656720.1698656720.1701170775.2; __utmb=223695111.0.10.1701170775; __utmc=223695111; __utmz=223695111.1701170775.2.2.utmcsr=open.weixin.qq.com|utmccn=(referral)|utmcmd=referral|utmcct=/; push_noty_num=0; push_doumail_num=0; __yadk_uid=bdyEdGw5LBo9dXxUEYdWEygyv1MkelW3; ll="118159"; frodotk_db="ef37e0cdfc6851d8cda7a269f538f588"; _vwo_uuid_v2=D3AA59641F59DCBAC831E95557CC131F7|984fdef9e1fa1ff456b997f6b8bb588b' , "User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0" } try : res = requests.get(url, headers=headers) if res.status_code == 200 : return res.text except : return None def parse_html (html ): soup = BeautifulSoup(html, "lxml" ) list = soup.find("ol" , class_="grid_view" ).find_all("li" ) for li in list : rank = li.find("em" , class_="" ).string img = li.find('a' ).find("img" ).get("src" ) title = li.find("span" , class_="title" ).string author, type = li.find('p' , class_="" ).text.strip().split("\n " ) score = li.find("span" , class_="rating_num" ).string review_count = li.find("div" , class_="star" ).find_all("span" )[-1 ].string print (rank, title) best_comment_elem = li.find("span" , class_="inq" ) best_comment = best_comment_elem.string if best_comment_elem != None else "" yield [rank, img, title, author, type , score, review_count, best_comment] max_col_width_zh = [0 ] * 8 def write_to_xlsx (index, item ): for col, content in enumerate (item): sheet.write(index, col, content) if len (content.encode('gb18030' )) > max_col_width_zh[col]: max_col_width_zh[col] = len (content.encode('gb18030' )) book = xlwt.Workbook() sheet = book.add_sheet("豆瓣电影 Top 250" , cell_overwrite_ok=True ) index = 0 headers = ['Rank' , 'Image' , 'Title' , 'Author' , 'Type' , 'Score' , 'Review Count' , 'Best Comment' ] write_to_xlsx(index, headers) index += 1 for start in range (0 , 225 +1 , 25 ): url = f"https://movie.douban.com/top250?start={start} " html = request_url(url) items = parse_html(html) for item in items: write_to_xlsx(index, item) index += 1 max_col_width = [width * 256 for width in max_col_width_zh] for col, width in enumerate (max_col_width): sheet.col(col).width = width book.save("top250_movies.xls" )
效果,自适应宽度存在问题,不知道怎么回事,还是在 Excel 里双击列右侧吧。
实现细节 通过 find 解析 HTML 获取信息 class_ 类似于 select 中的 .,找元素的子元素就 find().find() 这个操作类似 select 中的 。
自适应宽度(有问题) 由于存在中文,需要先按 gb18030 编码再获取长度。excel中列宽的最小宽度是 1/256,一个字符(汉字还是英文存疑)占用 256 个宽度,因此要将字符串长度乘 256 的到最终宽度。但是最终的效果是列宽明显长于内容宽度,怀疑不是所有字符都占用256个宽度
空元素处理
对于缺失元素,通过判断其是否缺失来赋值其内容或空字符串。
Selenium Library 在爬虫的第一步,即通过浏览器控制台 / burpsuite 抓包获取 headers,这也是很简单的一步,因此也有现成的库可以使用,不要让一窍不通的用户自己获取。
Edeg 官方教程:https://learn.microsoft.com/en-us/microsoft-edge/webdriver-chromium/?tabs=python
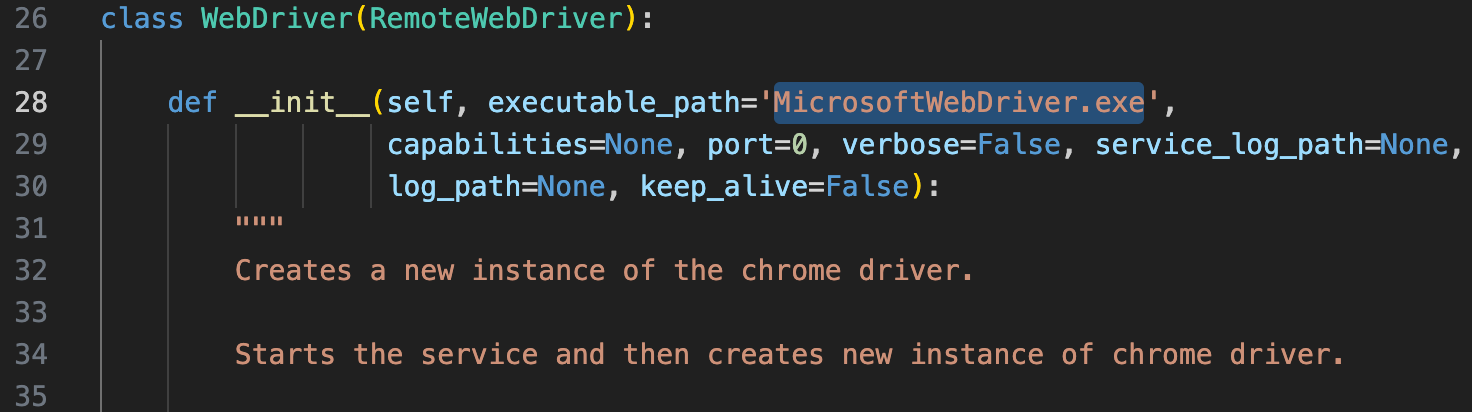
msedgedrive 在 macos 上存在一些问题(估计是 Microsoft 看不惯 Apple,一直没修),需要手动指定 Unix 可执行文件(Unix 无拓展名),且需要指定 capabilities 为空或者 capabilities.platformName=”mac”,否则就会自动认为是在环境变量下搜索 exe 文件,且平台为 Windows。
更新. Selenium 4 对 Edge 的支持大幅提升,集成了 msedge-selenium-tools ,不需要再这么做了。
控制台审查元素功能可以快速获取元素信息,鼠标放在元素上时可以显示 CSS Selector 所需的值。
剩下的见 ipynb。
Demo 3: Bilibili 所有 TOEFL 视频 & Phantomjs Library 写在前面 按照教程这里应该使用 Phantomjs Library 来实现无前端无感爬取,但这个方法已被 selenium 废弃,取而代之的是其他浏览器的 headless 模式,为了使用 Edge 的 headless 模式,需要升级到 Selenium 4。
升级注意事项:Upgrade to Selenium 4 | Selenium
语法没什么大变化,但是对 Edge 的支持大幅提升,且可以兼容 Selenium 3 的代码。
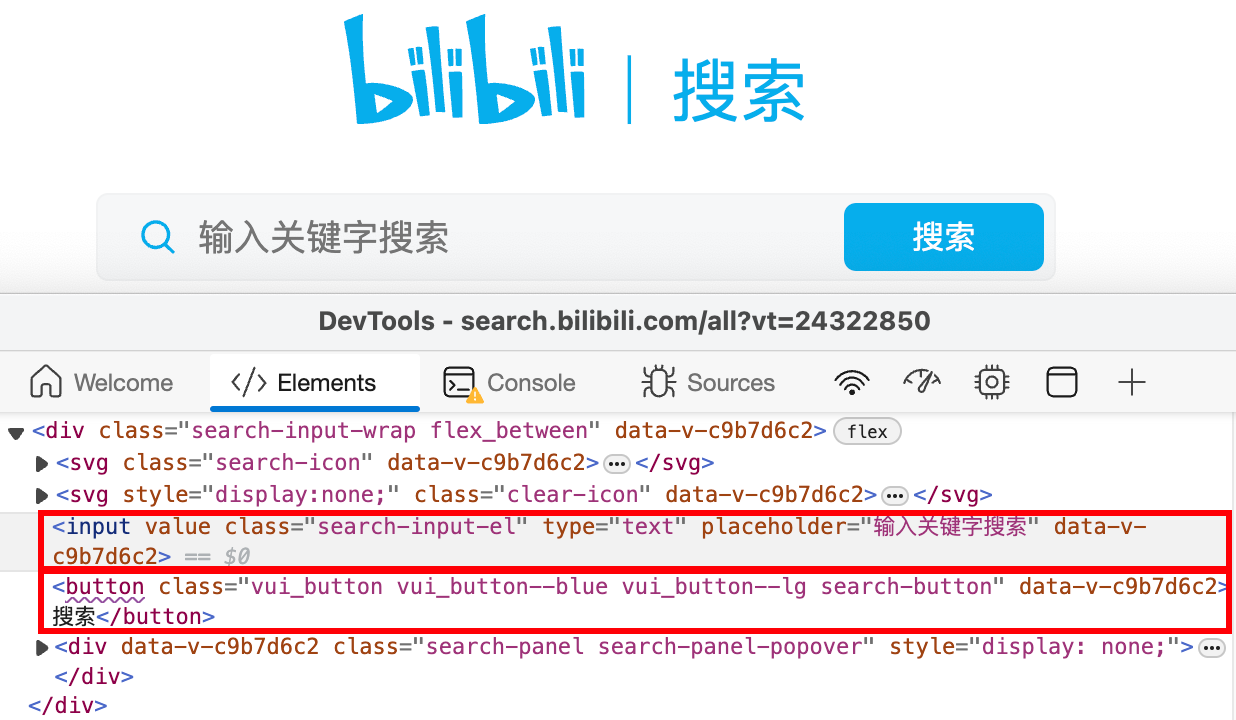
分析 目标 url:https://search.bilibili.com
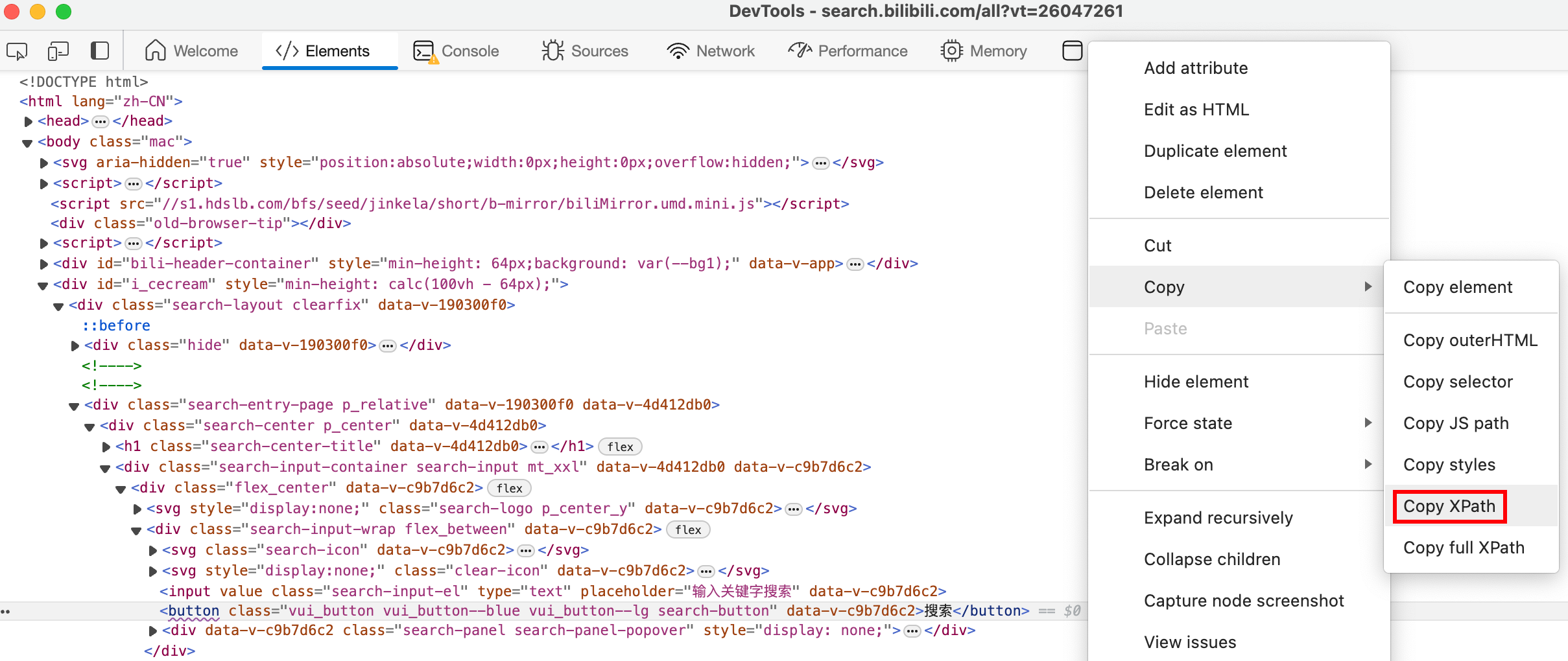
1. 元素信息
可直接复制其 XPath,通过 By.XPATH 查找元素。复制 CSS Selector 同理。
2. 通过 GET Request 参数 ?keyword=TOEFL&page=3&o=60,keyword 和 page 指定页数,o 由 page 确定,不是自由参数。
3. 所需信息
名称、链接、播放量、弹幕量、up主、投稿时间
代码定位自寻
因为是模拟手动点击,因此也不需要 headers。
代码实现 Selenium Waits技术:5. 等待页面加载完成(Waits) — Selenium-Python中文文档 2 documentation (selenium-python-zh.readthedocs.io)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 from bs4 import BeautifulSoupfrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.edge.options import Optionsfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECimport csvimport timedef parse_html (curr_page, html ): soup = BeautifulSoup(html, "lxml" ) list = soup.find('div' , class_='video-list row' ).find_all("div" , class_="bili-video-card" , limit=25 ) for item in list : title = item.find("h3" , class_="bili-video-card__info--tit" ).get("title" ) view_counts = item.find_all("span" , class_="bili-video-card__stats--item" )[0 ].find("span" ).text danmu_counts = item.find_all("span" , class_="bili-video-card__stats--item" )[1 ].find("span" ).text author = item.find("span" , class_="bili-video-card__info--author" ).text date = item.find("span" , class_="bili-video-card__info--date" ).text[3 :] print (title) yield [curr_page, title, view_counts, danmu_counts, author, date] options = Options() options.add_argument("headless" ) driver = webdriver.Edge(options = options) driver.get("https://search.bilibili.com/" ) wait = WebDriverWait(driver, 10 ) input_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "input.search-input-el" ))) search_elem = wait.until(EC.element_to_be_clickable((By.XPATH, '//button[@class="vui_button vui_button--blue vui_button--lg search-button"]' ))) with open ("TOEFL_videos.csv" , 'w' ) as f: csv_writer = csv.writer(f) csv_writer.writerow(["Page" , "Title" , "View Counts" , "Danmu Counts" , "Author" , "Date" ]) curr_page = 1 while True : print () print (curr_page) if curr_page == 1 : input_elem.send_keys("TOEFL" ) search_elem.click() lastpage_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div.vui_pagenation--btns > button:nth-last-child(2)" ))) total_page = int (lastpage_elem.text) else : next_page_button = wait.until(EC.element_to_be_clickable((By.XPATH, '//button[@class="vui_button vui_pagenation--btn vui_pagenation--btn-side" and contains(text(), "下一页")]' ))) next_page_button.click() time.sleep(3 ) wait.until(EC.presence_of_element_located((By.XPATH, '//div[@class="video-list row"]' ))) wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, '.vui_button.vui_button--active.vui_button--active-blue.vui_button--no-transition.vui_pagenation--btn.vui_pagenation--btn-num' ), str (curr_page))) html = driver.page_source items = parse_html(curr_page, html) for item in items: csv_writer.writerow(item) curr_page += 1 if curr_page == total_page + 1 : break driver.quit()
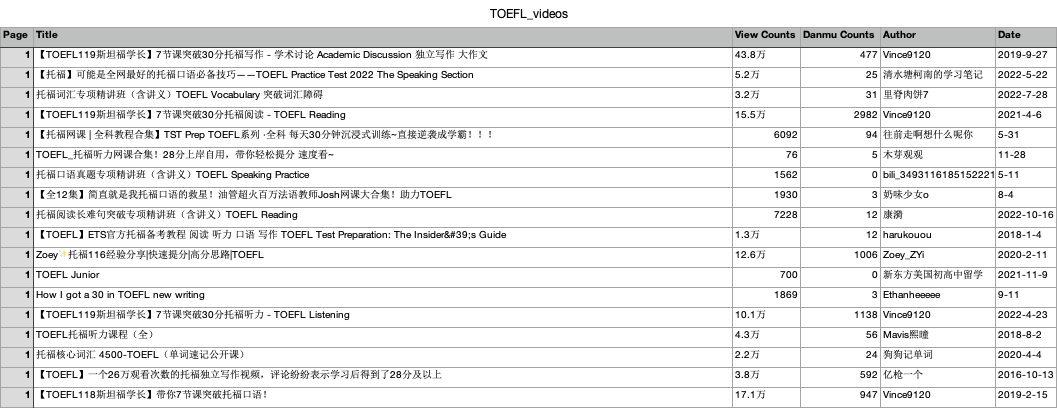
爬取结果
实现细节 稳健地获取元素 网站可能会更改元素层级,但其他信息一般不会更改。因此,尽量不要用控制台复制的 XPath 绝对路径,可以用元素种类、类、id、元素内文本等信息直接指定元素。
next_page_button = wait.until(EC.element_to_be_clickable((By.XPATH, '//button[@class="vui_button vui_pagenation--btn vui_pagenation--btn-side" and contains(text(), "下一页")]')))
稳健地爬取 如果每页等待时间过短,程序会重复抓取同一页,最简单的办法是直接 time.sleep(3),要比 Waits 简单稳健。
程序的整体完成时间在一天左右,主要困难在于选择元素和稳健选择元素。
Parse Json data 教程在这里以微信网页版为例,截止目前(20231201)微信网页版已停用,因此跳过。
事实上 Demo1 的 json 版已经能很好地解析 / 写入 json 数据了。
更多见 Demo 8
Multi-Threading & Thread Pool 常用的多线程模块:threading、Queue
我觉得线程可以理解为隧道,在开车过程中挖隧道和炸隧道都是比较耗资源的,所以最好在 python 进程启动时就创建好有很多线程的线程组(大型隧道组),也不销毁,用的时候就给它指定任务。
这个比较重要,从ipynb复制过来了。
单线程 1 2 3 4 5 6 7 8 9 10 11 import timedef moyu (name, delay, counter ): while counter: time.sleep(delay) print (f'{name} 开始摸鱼 {time.strftime("%Y-%m-%d %H:%M:%S" , time.localtime())} ' ) counter -= 1 if __name__ == '__main__' : moyu('WanpengXu' ,1 ,20 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 WanpengXu 开始摸鱼 2023-12-02 10:07:46 WanpengXu 开始摸鱼 2023-12-02 10:07:47 WanpengXu 开始摸鱼 2023-12-02 10:07:48 WanpengXu 开始摸鱼 2023-12-02 10:07:49 WanpengXu 开始摸鱼 2023-12-02 10:07:50 WanpengXu 开始摸鱼 2023-12-02 10:07:51 WanpengXu 开始摸鱼 2023-12-02 10:07:52 WanpengXu 开始摸鱼 2023-12-02 10:07:53 WanpengXu 开始摸鱼 2023-12-02 10:07:54 WanpengXu 开始摸鱼 2023-12-02 10:07:55 WanpengXu 开始摸鱼 2023-12-02 10:07:56 WanpengXu 开始摸鱼 2023-12-02 10:07:57 WanpengXu 开始摸鱼 2023-12-02 10:07:58 WanpengXu 开始摸鱼 2023-12-02 10:07:59 WanpengXu 开始摸鱼 2023-12-02 10:08:00 WanpengXu 开始摸鱼 2023-12-02 10:08:01 WanpengXu 开始摸鱼 2023-12-02 10:08:02 WanpengXu 开始摸鱼 2023-12-02 10:08:03 WanpengXu 开始摸鱼 2023-12-02 10:08:04 WanpengXu 开始摸鱼 2023-12-02 10:08:05
多线程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import timeimport threadingclass MyThread (threading.Thread): def __init__ (self,thread_ID, name, delay, counter ): threading.Thread.__init__(self) self.thread_ID = thread_ID self.name = name self.delay = delay self.counter = counter def run (self ): print ("开始线程:" + self.name) moyu(self.name, self.delay, self.counter) print ("退出线程:" + self.name) def moyu (thread_name, delay, counter ): while counter: time.sleep(delay) print (f'{thread_name} 开始摸鱼 {time.strftime("%Y-%m-%d %H:%M:%S" , time.localtime())} ' ) counter -= 1 if __name__ == '__main__' : thread1 = MyThread(1 , "小明" , 1 , 10 ) thread2 = MyThread(2 , "小红" , 2 , 10 ) thread1.start() thread2.start() thread1.join() thread2.join() print ("退出主线程" )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 开始线程:小明 开始线程:小红 小明 开始摸鱼 2023-12-02 10:10:45 小红 开始摸鱼 2023-12-02 10:10:46 小明 开始摸鱼 2023-12-02 10:10:46 小明 开始摸鱼 2023-12-02 10:10:47 小红 开始摸鱼 2023-12-02 10:10:48 小明 开始摸鱼 2023-12-02 10:10:48 小明 开始摸鱼 2023-12-02 10:10:49 小红 开始摸鱼 2023-12-02 10:10:50 小明 开始摸鱼 2023-12-02 10:10:50 小明 开始摸鱼 2023-12-02 10:10:51 小红 开始摸鱼 2023-12-02 10:10:52 小明 开始摸鱼 2023-12-02 10:10:52 小明 开始摸鱼 2023-12-02 10:10:53 小红 开始摸鱼 2023-12-02 10:10:54 小明 开始摸鱼 2023-12-02 10:10:54 退出线程:小明 小红 开始摸鱼 2023-12-02 10:10:56 小红 开始摸鱼 2023-12-02 10:10:58 小红 开始摸鱼 2023-12-02 10:11:00 小红 开始摸鱼 2023-12-02 10:11:02 小红 开始摸鱼 2023-12-02 10:11:04 退出线程:小红 退出主线程
用 ThreadPoolExecutor 管理多线程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import timeimport threadingfrom concurrent.futures import ThreadPoolExecutordef moyu (name, delay, counter, lock ): with lock: print (threading.current_thread().name) while counter: time.sleep(delay) with lock: print (f'{name} 开始摸鱼 {time.strftime("%Y-%m-%d %H:%M:%S" , time.localtime())} ' ) counter -= 1 if __name__ == '__main__' : pool = ThreadPoolExecutor(max_workers=20 ) lock = threading.Lock() for i in range (5 ): pool.submit(moyu, f'WanpengXu{i} ' , 1 , 4 , lock) pool.shutdown(wait=True )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ThreadPoolExecutor-0_0 ThreadPoolExecutor-0_2 ThreadPoolExecutor-0_1 ThreadPoolExecutor-0_3 ThreadPoolExecutor-0_4 WanpengXu1 开始摸鱼 2023-12-02 10:17:27 WanpengXu4 开始摸鱼 2023-12-02 10:17:27 WanpengXu0 开始摸鱼 2023-12-02 10:17:27 WanpengXu2 开始摸鱼 2023-12-02 10:17:27 WanpengXu3 开始摸鱼 2023-12-02 10:17:27 WanpengXu1 开始摸鱼 2023-12-02 10:17:28 WanpengXu4 开始摸鱼 2023-12-02 10:17:28 WanpengXu0 开始摸鱼 2023-12-02 10:17:28 WanpengXu3 开始摸鱼 2023-12-02 10:17:28 WanpengXu2 开始摸鱼 2023-12-02 10:17:28 WanpengXu0 开始摸鱼 2023-12-02 10:17:29 WanpengXu1 开始摸鱼 2023-12-02 10:17:29 WanpengXu2 开始摸鱼 2023-12-02 10:17:29 WanpengXu4 开始摸鱼 2023-12-02 10:17:29 WanpengXu3 开始摸鱼 2023-12-02 10:17:29 WanpengXu0 开始摸鱼 2023-12-02 10:17:30 WanpengXu2 开始摸鱼 2023-12-02 10:17:30 WanpengXu4 开始摸鱼 2023-12-02 10:17:30 WanpengXu1 开始摸鱼 2023-12-02 10:17:30 WanpengXu3 开始摸鱼 2023-12-02 10:17:30
用 Queue 管理多线程 这个示例的逻辑和上面的不太一样,是5个人一共 20个任务,每个任务只摸1条鱼;上面的是5个人每人 1个任务,每个任务摸4条鱼。结果都是每秒钟5个人摸鱼,4s末时任务结束。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import timeimport threadingfrom queue import Queueclass CustomThread (threading.Thread): def __init__ (self, queue, delay, lock ): threading.Thread.__init__(self) self.queue = queue self.delay = delay self.lock = lock def run (self ): while True : task = self.queue.get() task(self.delay, self.lock) self.queue.task_done() def moyu (delay, lock ): time.sleep(delay) with lock: print (f'{threading.current_thread().name} 开始摸鱼 {time.strftime("%Y-%m-%d %H:%M:%S" , time.localtime())} ' ) def queue_pool (): queue = Queue(5 ) lock = threading.Lock() for _ in range (queue.maxsize): t = CustomThread(queue, 1 , lock) t.daemon = True t.start() for i in range (20 ): queue.put(moyu) queue.join() if __name__ == '__main__' : queue_pool()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Thread-4 开始摸鱼 2023-12-02 10:20:20 Thread-8 开始摸鱼 2023-12-02 10:20:20 Thread-5 开始摸鱼 2023-12-02 10:20:20 Thread-7 开始摸鱼 2023-12-02 10:20:20 Thread-6 开始摸鱼 2023-12-02 10:20:20 Thread-8 开始摸鱼 2023-12-02 10:20:21 Thread-7 开始摸鱼 2023-12-02 10:20:21 Thread-6 开始摸鱼 2023-12-02 10:20:21 Thread-4 开始摸鱼 2023-12-02 10:20:21 Thread-5 开始摸鱼 2023-12-02 10:20:21 Thread-8 开始摸鱼 2023-12-02 10:20:22 Thread-7 开始摸鱼 2023-12-02 10:20:22 Thread-5 开始摸鱼 2023-12-02 10:20:22 Thread-4 开始摸鱼 2023-12-02 10:20:22 Thread-6 开始摸鱼 2023-12-02 10:20:22 Thread-5 开始摸鱼 2023-12-02 10:20:23 Thread-6 开始摸鱼 2023-12-02 10:20:23 Thread-8 开始摸鱼 2023-12-02 10:20:23 Thread-4 开始摸鱼 2023-12-02 10:20:23 Thread-7 开始摸鱼 2023-12-02 10:20:23
DEMO 4: 每日妹子图 分析 目标url:https://meizi8.com/
1. 通过 url 地址https://meizi8.com/page/n 翻到第 n 页
2. 每页有 16 个帖子(预览图),每个帖子内有 1~10 张不等图片,page -> post -> picture
3. 所需信息
帖子内的所有图片
程序思路 先循环构造每页的地址,设计一个函数从每页中获取16个帖子的地址,再设计一个函数下载每个帖子内的所有图片,可以创建 n 个线程每次爬取 n 个帖子内的所有图片。
除了多线程那三行代码没什么新技术。
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 from bs4 import BeautifulSoupfrom concurrent.futures import ThreadPoolExecutorfrom concurrent.futures import ProcessPoolExecutorimport osimport timeimport requestsimport threadingimport multiprocessingheaders = { "Cookie" : '__51vcke__Js6m73nB7LGdoohB=ab53e2f7-6d63-552c-b3cb-c8ba9f968f03; __51vuft__Js6m73nB7LGdoohB=1701484179543; __51uvsct__Js6m73nB7LGdoohB=2; __vtins__Js6m73nB7LGdoohB=%7B%22sid%22%3A%20%22aa316a0d-e89c-5917-b4f7-a179bdfec266%22%2C%20%22vd%22%3A%2022%2C%20%22stt%22%3A%203514223%2C%20%22dr%22%3A%20153537%2C%20%22expires%22%3A%201701527611751%2C%20%22ct%22%3A%201701525811751%7D' , "Referer" :'https://meizi8.com/' , "User-Agent" : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0' } def request_page (url ): try : res = requests.get(url, headers=headers) if res.status_code == 200 : return res.text except : return None def get_post_urls_from_page (html ): post_urls_per_page = [] soup = BeautifulSoup(html, "lxml" ) posts = soup.find("div" , attrs={"class" : "masonry" , "id" : "masonry" }).find_all("article" , attrs={"class" : "masonry-item" }) for post in posts: post_url = post.find("a" , attrs={"class" : "entry-thumbnail" }).get("href" ) post_urls_per_page.append(post_url) return post_urls_per_page def download_pics_from_post (url ): post_html = request_page(url) soup = BeautifulSoup(post_html, "lxml" ) title = soup.find("h1" , attrs={"class" : "entry-title" }).string pic_urls = [] pic_items = [item for item in soup.find("div" , attrs={"class" : "entry themeform" }).find_all('p' ) if item.get("style" ) == None ] for pic_item in pic_items: pic_url = pic_item.find("img" ).get("src" ) pic_urls.append(pic_url) if not os.path.exists(f"{title} " ): os.mkdir(f"{title} " ) for pic_url in pic_urls: filename = f'{title} /{pic_url.split("/" )[-1 ]} ' print (f"{multiprocessing.current_process().name} is downloading {pic_url} " ) with open (filename, "wb" ) as f: img = requests.get(pic_url, headers=headers).content f.write(img) if __name__ == "__main__" : if not os.path.exists("meizi8" ): os.mkdir("meizi8" ) os.chdir("meizi8" ) post_urls = [] for page in range (1 , 2 +1 ): page_url = f"https://meizi8.com/page/{page} " page_html = request_page(page_url) post_urls.extend(get_post_urls_from_page(page_html)) start_time = time.time() with ProcessPoolExecutor(max_workers=16 ) as exector: for post_url in post_urls: exector.submit(download_pics_from_post, post_url) end_time = time.time() elapsed_time = end_time - start_time print (elapsed_time)
单主线程时间:323.1215920448303
4线程时间:180.1571547985077
8线程时间:215.17093300819397
4进程时间:266.51773381233215
8进程时间:198.45511484146118
16进程时间:175.14416122436523
实现细节 404解决 加Refer
筛选不包含某属性的元素 对于这个 demo,部分 post 最后一项元素是引导链接,所以不能全部 `[:-1]。它和其他元素的区别在于它多了一个属性 style,因此可以利用这点筛去它,由于 chatgpt 给的 :not() 不能用。
1 pic_items = soup.find("div" , attrs={"class" : "entry themeform" }).find_all('p:not([style="text-align: center;"])' )
因此使用了简单的 get() 配合列表解析实现。
1 pic_items = [item for item in soup.find("div" , attrs={"class" : "entry themeform" }).find_all('p' ) if item.get("style" ) == None ]
GIL锁 代码执行速度瓶颈是网络请求时,Python 的全局解释器锁 (GIL) 会阻止多线程并行执行 Python 字节码。
因此这种情况适合使用多进程。
Multi-Processing & Process Pool 创建进程 1 2 3 4 5 6 7 from multiprocessing import Processfrom multiprocessing_func import funcif __name__ == '__main__' : p = Process(target=func, args=('WanpengXu' , ), name="P001" ) p.start() p.join()
1 hello, WanpengXu! I am P001.
用 Pool 或 ProcessPoolExecutor 管理多进程 Pool 和 ProcessPoolExecutor 不太一样
Pool.map 自动提交任务,同步处理所有任务
ProcessPoolExecutor.submit 手动提交任务,异步处理每个任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import timefrom multiprocessing import Poolfrom multiprocessing_func import sqrt_funcfrom concurrent.futures import ProcessPoolExecutorif __name__ == '__main__' : data = [1 , 2 , 3 , 4 , 5 , 6 ] start_time = time.time() result = [x ** 2 for x in data] print (result) end_time = time.time() print (end_time - start_time) start_time = time.time() with Pool(processes=5 ) as p: result = p.map (sqrt_func, data) print (result) end_time = time.time() print (end_time - start_time) start_time = time.time() with ProcessPoolExecutor(max_workers=5 ) as executor: futures = [executor.submit(sqrt_func, x) for x in data] result = [future.result() for future in futures] print (result) end_time = time.time() print (end_time - start_time)
1 2 3 4 5 6 [1, 4, 9, 16, 25, 36] 2.574920654296875e-05 [1, 4, 9, 16, 25, 36] 0.05546903610229492 [1, 4, 9, 16, 25, 36] 0.07867026329040527
工具函数需要单独放在另一个包中
1 2 3 4 5 6 7 import multiprocessingdef func (name ): print (f'hello, {name} ! I am {multiprocessing.current_process().name} .' ) def sqrt_func (x ): return x * x
DEMO 5: 豆瓣 Top 250 电影 进阶 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 from bs4 import BeautifulSoupimport csvimport xlwtimport requestsimport multiprocessingdef request_url (url ): headers = { "Cookie" : 'bid=r5NyipyS844; _pk_id.100001.4cf6=8d2637ab28beb521.1698656720.; dbcl2="220842516:kaSCAN2Yw5c"; __utmz=30149280.1701170775.3.3.utmcsr=open.weixin.qq.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmz=223695111.1701170775.2.2.utmcsr=open.weixin.qq.com|utmccn=(referral)|utmcmd=referral|utmcct=/; push_noty_num=0; push_doumail_num=0; __yadk_uid=bdyEdGw5LBo9dXxUEYdWEygyv1MkelW3; ll="118159"; _vwo_uuid_v2=D3AA59641F59DCBAC831E95557CC131F7|984fdef9e1fa1ff456b997f6b8bb588b; ck=u7Tj; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1701606524%2C%22https%3A%2F%2Fopen.weixin.qq.com%2F%22%5D; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.1380904537.1698110791.1701180703.1701606525.6; __utmb=30149280.0.10.1701606525; __utmc=30149280; __utma=223695111.603104195.1698656720.1701180703.1701606525.5; __utmb=223695111.0.10.1701606525; __utmc=223695111' , "User-Agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0" } try : res = requests.get(url, headers=headers) if res.status_code == 200 : return res.text except : return None def parse_html (html ): soup = BeautifulSoup(html, "lxml" ) list = soup.find("ol" , class_="grid_view" ).find_all("li" ) for li in list : rank = li.find("em" , class_="" ).string img = li.find('a' ).find("img" ).get("src" ) title = li.find("span" , class_="title" ).string author, type = li.find('p' , class_="" ).text.strip().split("\n " ) score = li.find("span" , class_="rating_num" ).string review_count = li.find("div" , class_="star" ).find_all("span" )[-1 ].string print (rank, title) best_comment_elem = li.find("span" , class_="inq" ) best_comment = best_comment_elem.string if best_comment_elem != None else "" yield [rank, img, title, author, type , score, review_count, best_comment] def write_to_csv (file_path, item ): with open (file_path, 'a' ) as f: csv_writer = csv.writer(f) csv_writer.writerow(item) def crawl_url (args ): file_path, url = args html = request_url(url) items = parse_html(html) for item in items: write_to_csv(file_path, item) if __name__ == '__main__' : file_path = "top250_movies_2.csv" with open (file_path, 'w' ) as f: csv_writer = csv.writer(f) csv_writer.writerow(['Rank' , 'Image' , 'Title' , 'Author' , 'Type' , 'Score' , 'Review Count' , 'Best Comment' ]) urls = [f"https://movie.douban.com/top250?start={start} " for start in range (0 , 225 +1 , 25 )] with multiprocessing.Pool(multiprocessing.cpu_count()) as pool: pool.map (crawl_url, [(file_path, url) for url in urls])
实现细节 并发写入 多进程并发写入文件很难,干脆用csv,每次写入都打开文件、新建句柄,因为传入writer句柄也不太容易
保证顺序 要保证顺序就更难,如果爬取内容本身有排名,那就乱序写入吧,爬好之后再排
Proxy & Proxy Pool 代理为别人的 IP 防止被封
免费代理:https://ip.ihuan.me
代理池:https://github.com/Python3WebSpider/ProxyPool
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import requestsdef request_url (url, proxies ): try : res = requests.get(url, proxies=proxies) if res.status_code == 200 : return res.text except : return None if __name__ == '__main__' : proxies = { 'http' : 'http://119.13.103.211:4153' , 'https' : 'https://119.13.103.211:4153' } html = request_url('http://httpbin.org/get' , proxies=proxies) print (html)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 { "args" : { "show_env" : "" } , "headers" : { "Accept-Encoding" : "" , "Host" : "httpbin.org" , "User-Agent" : "python-requests/2.31.0" , "X-Amzn-Trace-Id" : "Root=1-63156d33-528b16b838892ff15c5a4d2f" , "X-Forwarded-For" : "119.13.103.211" , "X-Forwarded-Port" : "80" , "X-Forwarded-Proto" : "http" } , "origin" : "119.13.103.211" , "url" : "http://httpbin.org/get?show_env" }
Log in / Sign in Cookies、抓包再提交form(这个还是别用了,抓到的密码肯定是加密的,里面说不定混了其他身份信息,导致封号)、Selenium模拟手动登录
Cookies 见1.3 和前面的每个Demo
POST Request 见 1.2 和 3
Selenium 模拟手动登陆 伪代码
1 2 3 4 5 6 username = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "帐号的selector" ))) password = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "密码的selector" ))) submit = wait.until(EC.element_to_be_clickable((By.XPATH, '按钮的xpath' ))) username.send_keys('你的帐号' ) password.send_keys('你的密码' )submit.click()
为了效率,可以在登录过后得到的cookie维护起来,然后调用requests或者scrapy等进行数据采集,这样数据采集的速度可以得到保证。
1 cookies = webdriver.get_cookies()
CAPTCHA Recognize 图形验证码:字符识别、字符识别后算数、空间推理(“请点击除了H以外的另一个倾斜字符”,我没遇到过)
行为验证码:滑动拼图、语序点选文字
这里有个项目,README 说原理是通过 selenium 绕过登陆验证,应该首先考虑绕过验证,无法绕过时再考虑通过验证。
https://github.com/Kr1s77/awesome-python-login-model
绕不过去的时候去这里找个合适的 SDK 让爬虫程序过验证:captcha · GitHub Topics
Character CAPTCHA Recognize 作者那时候还是使用传统数字图像处理方法,现在已经可以直接用 AI 了,除了找现成库以外还找网站获取验证码识别 API。
Slider CAPTCHA Recognize 手搓行为验证码识别稍微难点,要破解图片(部分网站无法直接获取图片)、识别缺口(这个似乎可以直接用图像处理的方法,毕竟缺口一般是很明显的,尝试cv2.matchTemplate),还需要匀速直线拖动(这个应该是全网站通用的)。
SDK Recommend 付费 API,1¥最多100次,个人用(抢课、抢讲座)足够:http://www.chaojiying.com/
免费 SDK:https://github.com/sml2h3/ddddocr
这个库结合了DL和传统图像处理方法,能做到通用验证码识别,有 Python Library。
pip install ddddocr
已知的一个问题(#29)是提供的模型不能区分大小写。
Appium Install Appium 是一个和 Selenium 功能相同的自动化测试软件,区别在于 Appium 对移动设备的支持更好。
offical doc: http://appium.io/
迪原创新 blog:https://www.dilatoit.com/zh/cn-blog/,提供了很多爬虫、自动化测试实践。
安装平台:
brew:跟 windows 的 Winget 和 ubuntu 的 apt-get 差不多,下载开源源码并编译为程序,比较好用。
—cask:下载编译好的软件包(一些闭源软件的.dmg/.pkg)
npm:appium基于nodejs构建的,所以用这个编译。
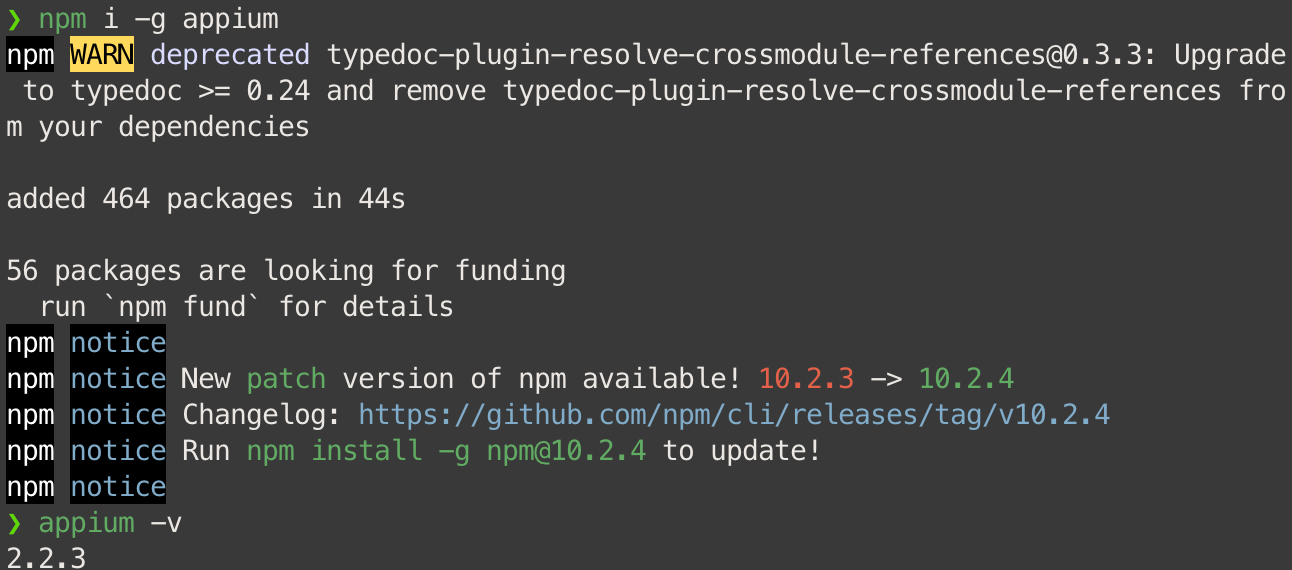
Install Appium npm install --location=global appium
或
npm i -g appium
Install Driver from Appium Android appium driver install uiautomator2
iOS 中文互联网上的纯 WebDriverAgent 方案已弃用,Appium 2 现使用 XCUITest,其基于 XCTest 和 WebDriverAgent 。
offical doc: https://appium.github.io/appium-xcuitest-driver
appium driver install xcuitest
Install Driver’s Dependencies Android 如果你不需要进行 Android 开发和 Java 开发,那么只需要安装 SKD 和 JDK(免费开源的OpenJDK,不是Oracle JDK),不需要 Android Studio 和 JAVA。
重要. 通过brew安装的 tools 和 platform-tools 在两个目录下,其他软件没办法通过 ANDROID_HOME 目录同时检测到他们,所以除非单独使用,否则不要用这种方法。
下载新版 SDK Cmdline-Tools(SDK Tools 已弃用 )和 SDK Platform-tools
下载 Android Studio 和应用工具 - Android 开发者 | Android Developers
SDK 平台工具版本说明 | Android 开发者 | Android Developers
手动创建 sdk 目录(下面这俩是伪代码,只能逐级创建)
1 2 mkdir /Users/wanpengxu/Library/Android/sdkmkdir /Users/wanpengxu/Library/Android/sdk/cmdline-tools
移动文件夹并重命名(一定要在 latest 目录下,否则 sdkmanager 不能安装东西)
1 2 3 cd /Users/wanpengxu/Library/Android/sdkmv /Users/wanpengxu/Downloads/cmdline-tools ./cmdline-tools/latestmv /Users/wanpengxu/Downloads/platform-tools ./
手动配置环境变量
1 2 3 echo 'export ANDROID_HOME="/Users/wanpengxu/Library/Android/sdk"' >> ~/.zshrcecho 'export PATH="$PATH:$ANDROID_HOME/cmdline-tools/latest:$ANDROID_HOME/platform-tools"' >> ~/.zshrcecho 'export PATH="$PATH:$ANDROID_HOME/cmdline-tools/latest/bin"' >> ~/.zshrc
:是 MacOS 环境变量的分割符,要确保以前的环境变量存在就要加 :$PATH(新的加在前面)或者 $PATH: (新的加在后面)
新版 SDK Cmdline-Tools 不集成 emulator,自己安装
sdkmanager "emulator"
还要再装一个 build-tools,虽然不会被检测,但是是必须要用的
安装时必须指定版本,在这里查看版本:SDK Build Tools 版本说明 | Android 开发者 | Android Developers
sdkmanager "build-tools;34.0.0"
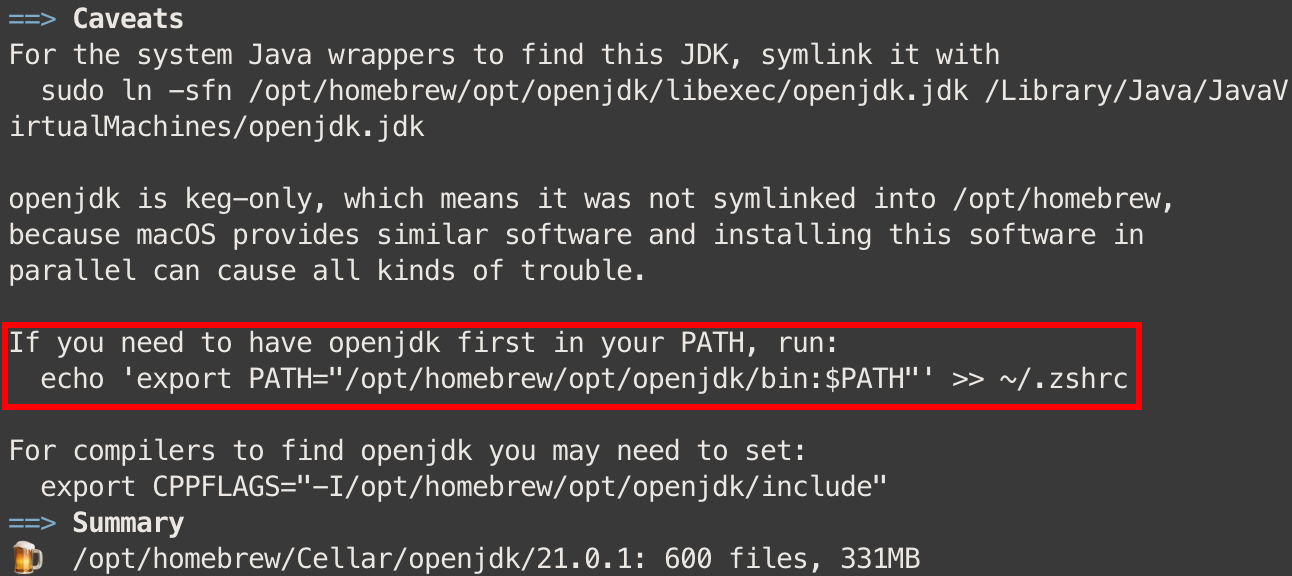
Openjdk brew install openjdk
提示我们要配置环境变量
通过查看目录发现 brew 为我们创建了一个软链接,拿它作为 JAVA_HOME
1 2 echo 'export JAVA_HOME="/opt/homebrew/opt/java"' >> ~/.zshrcecho 'export PATH="$PATH:$JAVA_HOME/bin"' >> ~/.zshrc
其实我觉得更改 /etc/paths 这种方式跟 windows 配置环境变量更像,但是 unix 系统好像都是写在命令行启动脚本里。
重启命令行或重载启动脚本后可用 java 命令。
iOS 直接从 Apple Store 里装
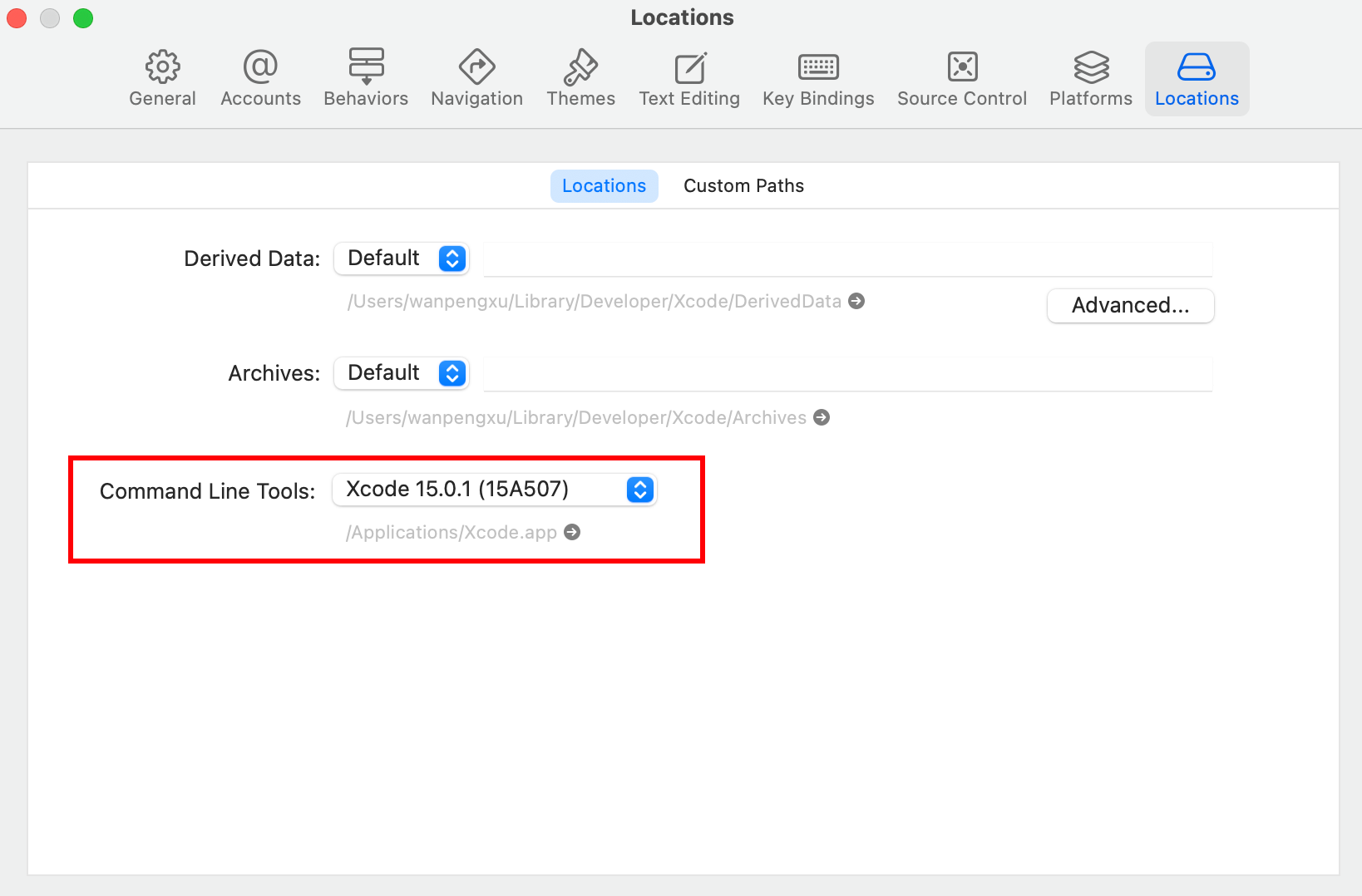
CLT要重新选择 一下,原本会显示(No CLT Selected)。
WDA 下载源码:https://github.com/appium/WebDriverAgent
打开Xcode进行编译安装
前提条件:登陆账户、下载 iOS 开发平台
Install Library in Language pip install Appium-Python-Client
Install Appium Inspector (new Appium Desktop) Releases · appium/appium-inspector (github.com)
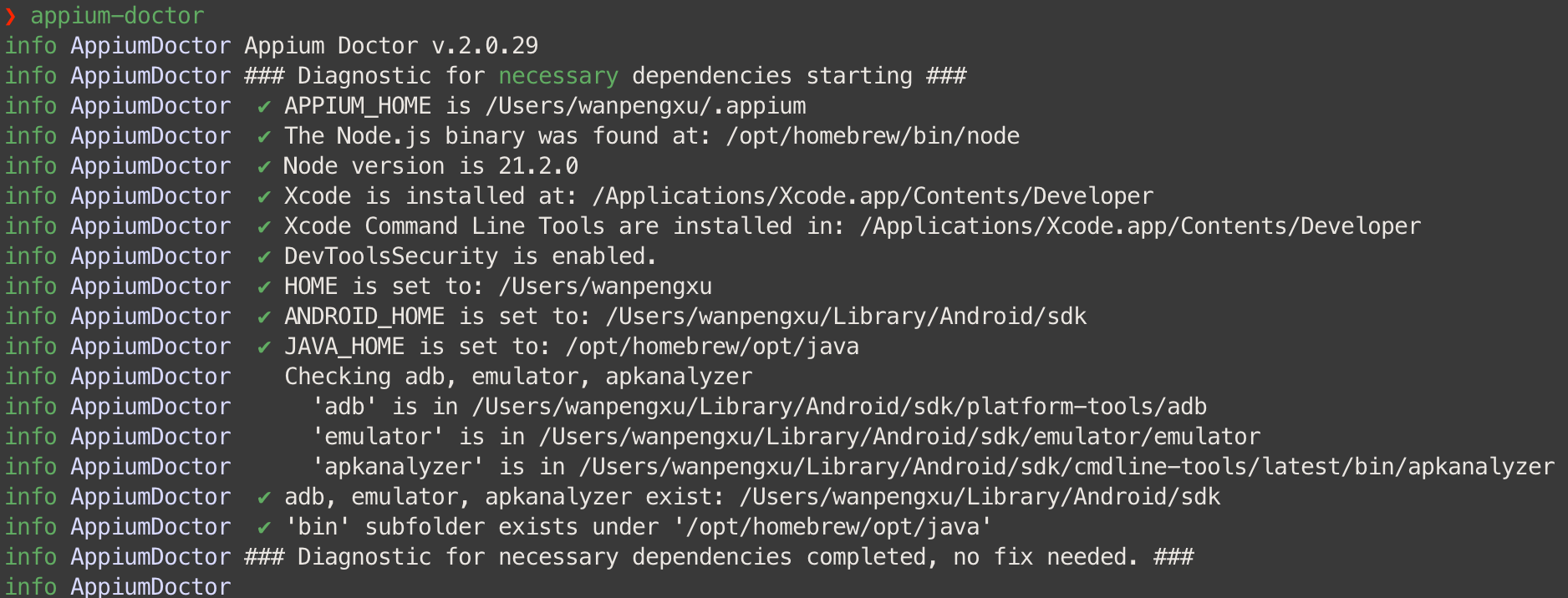
Check npm install -g @appium/doctor(appium-doctor 已弃用)
necessary 项全绿就可以了。
Appium Run 启动 appium server
appium
获取 activity
adb shell dumpsys activity top | grep ACTIVITY
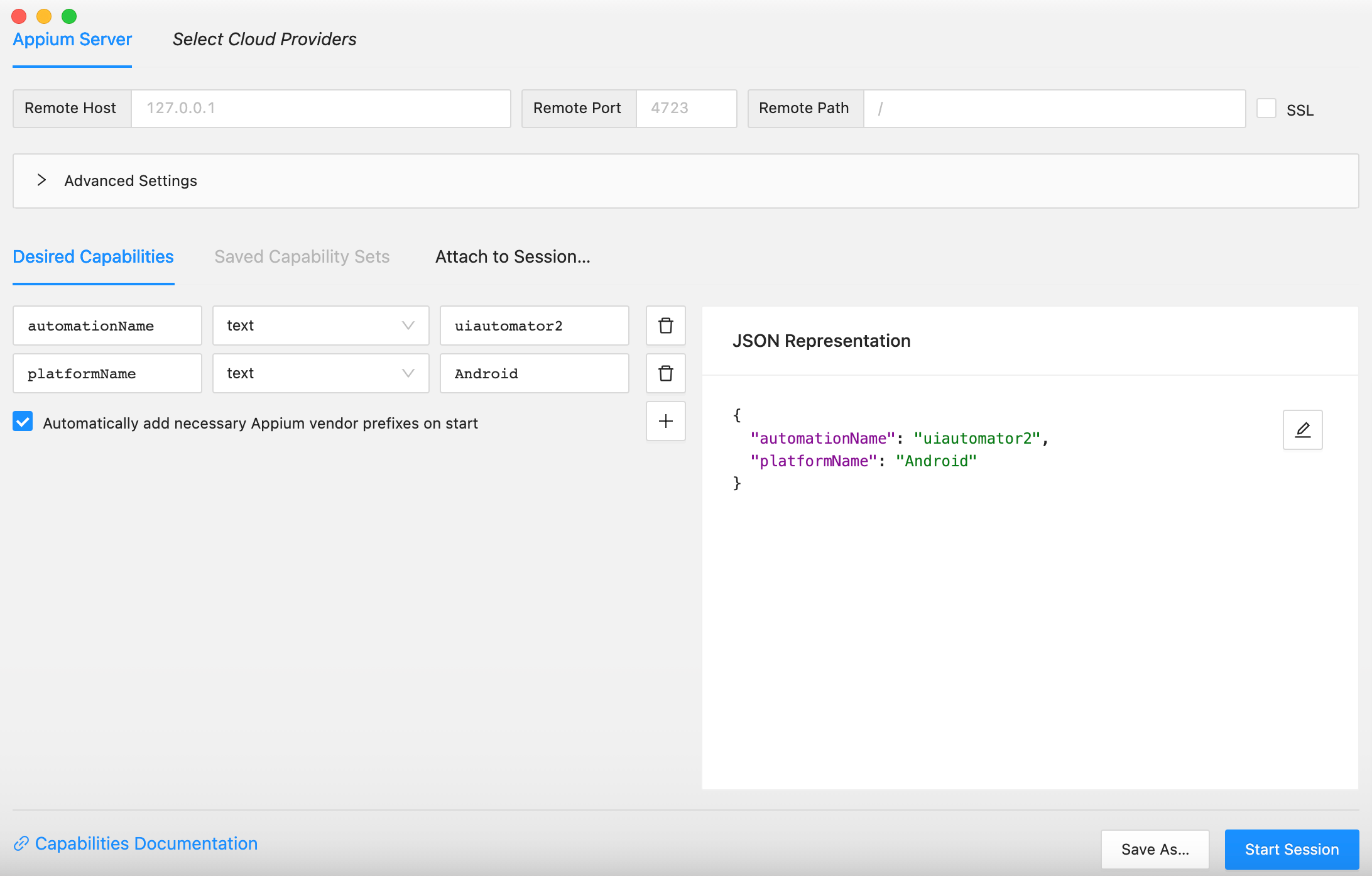
启动 appium inspector,capabilities 只填写最基本的两项,点击两次 Start Session。
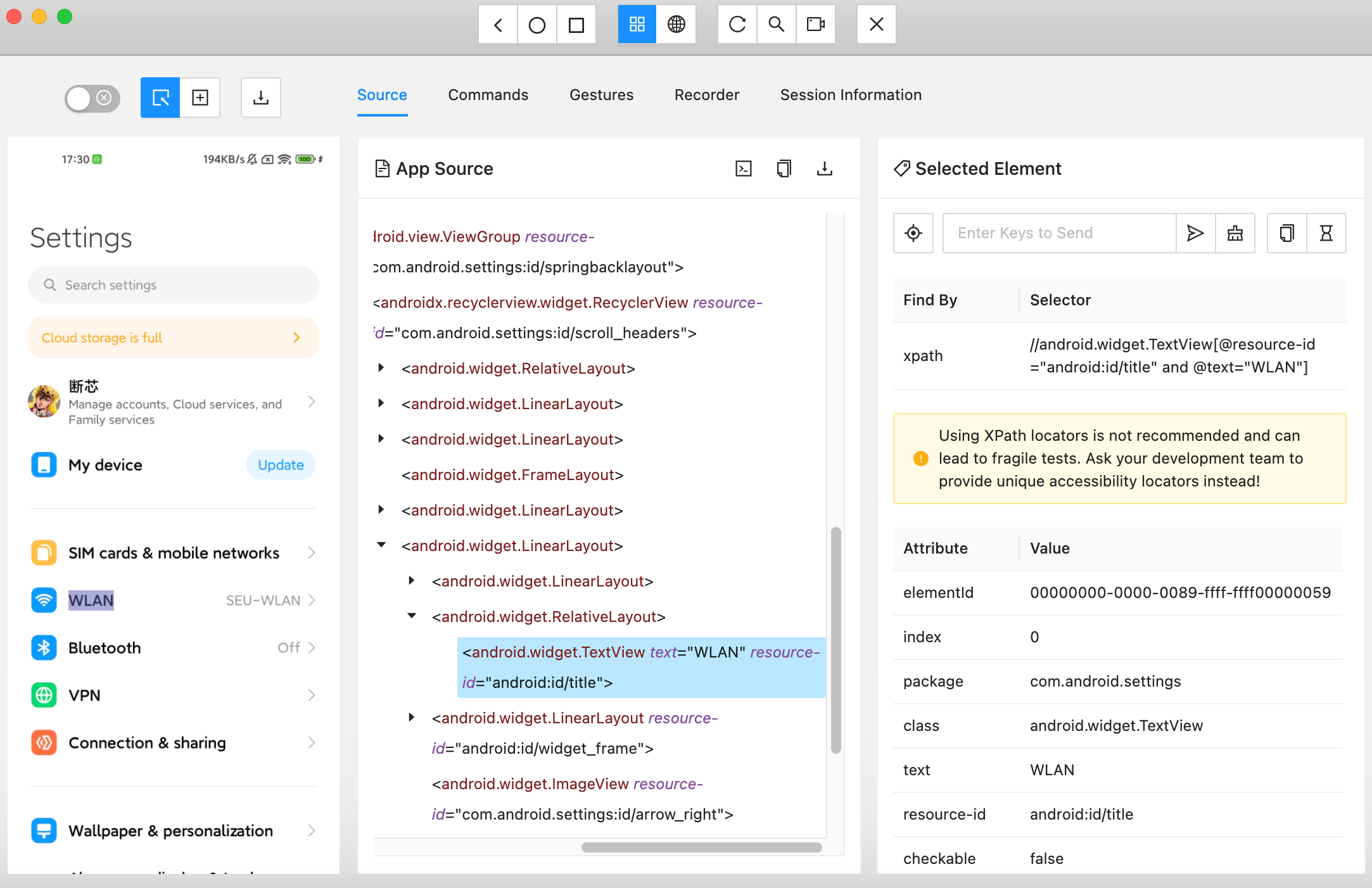
在这里可以获取元素的 XPath,也可以录制行为查看其对应脚本。
由于官方测试的 Battery 在 MIUI 中不在第一页显示范围内,需要 gesture,所以还是选择第一页的元素进行点击测试吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import unittestimport timefrom appium import webdriverfrom appium.options.android import UiAutomator2Optionsfrom appium.webdriver.common.appiumby import AppiumBycapabilities = dict ( platformName='Android' , automationName='uiautomator2' , deviceName='Android' , appPackage='com.android.settings' , appActivity='.MainSettings' , language='en' , locale='US' ) appium_server_url = 'http://localhost:4723' class TestAppium (unittest.TestCase): def setUp (self ) -> None : self.driver = webdriver.Remote(appium_server_url, options=UiAutomator2Options().load_capabilities(capabilities)) def tearDown (self ) -> None : pass def test_find_battery (self ) -> None : el = self.driver.find_element(by=AppiumBy.XPATH, value='//*[@text="WLAN"]' ) el.click() if __name__ == '__main__' : unittest.main()
1 2 3 4 5 . ---------------------------------------------------------------------- Ran 1 test in 5.717s OK
脚本启动后会把 appium inspector 的 session 顶掉,再次使用时需要重新 start session。
Demo 7: 知乎 Android 版文章 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 from appium import webdriverfrom appium.options.android import UiAutomator2Optionsfrom appium.webdriver.common.appiumby import AppiumByimport timecapabilities = dict ( platformName='Android' , automationName='uiautomator2' , deviceName='Android' , appPackage='com.zhihu.android' , appActivity='.app.ui.activity.MainActivity' , language='en' , locale='US' , noReset=True ) appium_server_url = 'http://localhost:4723' driver = webdriver.Remote(appium_server_url, options=UiAutomator2Options().load_capabilities(capabilities)) time.sleep(6 ) input_elem1 = driver.find_element(AppiumBy.ID, 'com.zhihu.android:id/query_container' ) input_elem1.click() input_elem2 = driver.find_element(AppiumBy.ID, 'com.zhihu.android:id/input' ) input_elem2.send_keys('科研实习' ) search_elem = driver.find_element(AppiumBy.ID, 'com.zhihu.android:id/cancel' ) search_elem.click() filter_elem = driver.find_element(AppiumBy.ID, 'com.zhihu.android:id/classify_filter_btn' ) filter_elem.click() passage_elem = driver.find_element(AppiumBy.XPATH, '//*[@text="只看文章"]' ) passage_elem.click() filter_elem.click() for page in range (5 ): item_elems = driver.find_elements(AppiumBy.XPATH, '//android.view.View[@resource-id="root"]/android.view.View/android.view.View/android.widget.ListView/android.view.View' ) for item in item_elems: text_part = item.find_elements(AppiumBy.CLASS_NAME, 'android.widget.TextView' ) if len (text_part) == 0 or text_part[0 ].text == '相关搜索' : continue print (text_part[0 ].text) driver.swipe(555 , 1850 , 555 , 500 , duration=300 ) time.sleep(1 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 【长期有效】北京大学科研实习招募 科研实习丨清华大学智能计算实验室招收科研助理/实习生 (可远程) 科研实习丨清华大学交叉信息研究院招收科研实习生 抓紧!一大波大厂&科研实习机会可别错过(含腾讯AI Lab,清华大学课题组) 科研实习 | 腾讯优图(深圳)实验室实习生招聘 清华赵行老师,招收视觉/机器人科研实习生 HISLab招收暑期科研实习生(可远程)5.2 科研实习丨香港科技大学统计机器学习实验室招收科研实习生(目前为远程) 科研实习 | 北大贺笛老师招收GNN方向科研实习生 科研实习 | 北大张文涛教授招收GNN科研实习生/RA 科研实习丨北京大学国际机器学习研究中心招收科研实习生/RA 【实习内推】中科院-科研助理实习生 【实习内推】中科院-科研助理实习生 美团广告平台模型组科研实习生招聘 科研招聘 |上海人工智能实验室招聘实习生 独家解读丨科研实习该怎么找、怎么做 科研实习丨西湖大学2023年暑期科研实习公告 科研实习丨西湖大学2023年暑期科研实习公告 美团广告平台模型组科研实习生招聘 科研实习丨麻省理工学院韩松教授实验室招收科研实习生(可远程) UC Santa Cruz王鑫教授招收多名暑期科研实习生(summer 2022, NLP/CV/AI)
实现细节 不同于从浏览器直接获取 HTML response,这种通过 Appium 对 screenshot 逆向取得 XML 的方式只能获取到显示的内容,不能获取到没显示的内容(文字后的超链接、截断前的字符串等等)。
通过 XPath 获取元素的所有直接子节点 因为逆向出的 XML 信息不全导致筛选困难,无法精确捕获 item 所在的元素,所以最好尽可能通过 // 定位到树结构的分岔点,然后通过 / 按父子关系选出所有直接子节点。
顺带一提,获取所有的子节点用的是 //node()
信息获取逻辑 因为每个 screenshot 都是独立的,因此滑动后的页面和滑动前的页面无法联系起来,所以最好处理完滑动前页面的所有信息,再进行滑动,又因为滑动操作无法智能地将滑动后的页面完全与滑动前的页面分离、没有重叠,因此每次获取页面的信息都可能会发生重复。
Write to MySQL 与 MySQL 数据库交互主要有这几个库, PyMySQL, MySQLClient, SQLAlchemy。第一个是 pyhton 实现,第二个是 C 实现,第三个可以配合 pandas 将 csv 写入 mysql。
我觉得会个 pymysql 就行了,使用方法很简单,把 mysql 语句装进字符串即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import pymysqldb = pymysql.connect("localhost" , "root" , "root" , "test_library" ) cursor = db.cursor() sql = "insert into test_table(name, age) values ('WanpengXu', 22)" try : cursor.execute(sql) db.commit() except : db.rollback() db.close()
Write to MongoDB MongoDB 是一种非关系型数据库(NOSQL,Not Only SQL),它不以二维表的形式存储数据,而是以 JSON (键值对)的形式存储数据。
没什么用,不用学。
Scrapy Scrapy 是一个爬虫框架,集成了请求(requests)、解析(beautifulsoup)、存储(csv, xlwt, json)这些操作。
scrapy 同时还是一个独立的程序,你可以直接调用它而不需经过 python。
以下一节中要爬的网站 https://tianchi.aliyun.com/competition/activeList 为例。
pip install scrapy
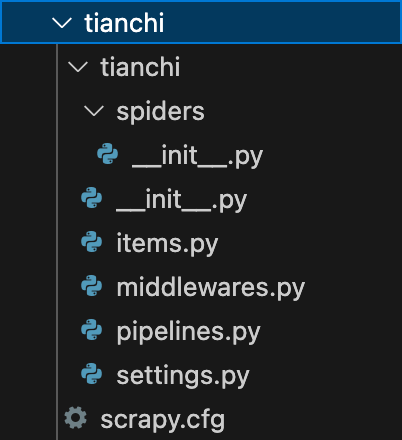
首先新建 scrapy 项目
scrapy startproject tianchi
其中,
spiders:存放爬虫代码的目录
items.py:定义存储数据的字段
middlewares.py:中间件,爬虫响应间歇执行的代码
pipelines.py:定义存储目标的信息,如连接 MySQL 所需的信息
settings.py:定义爬虫的配置,如 header信息
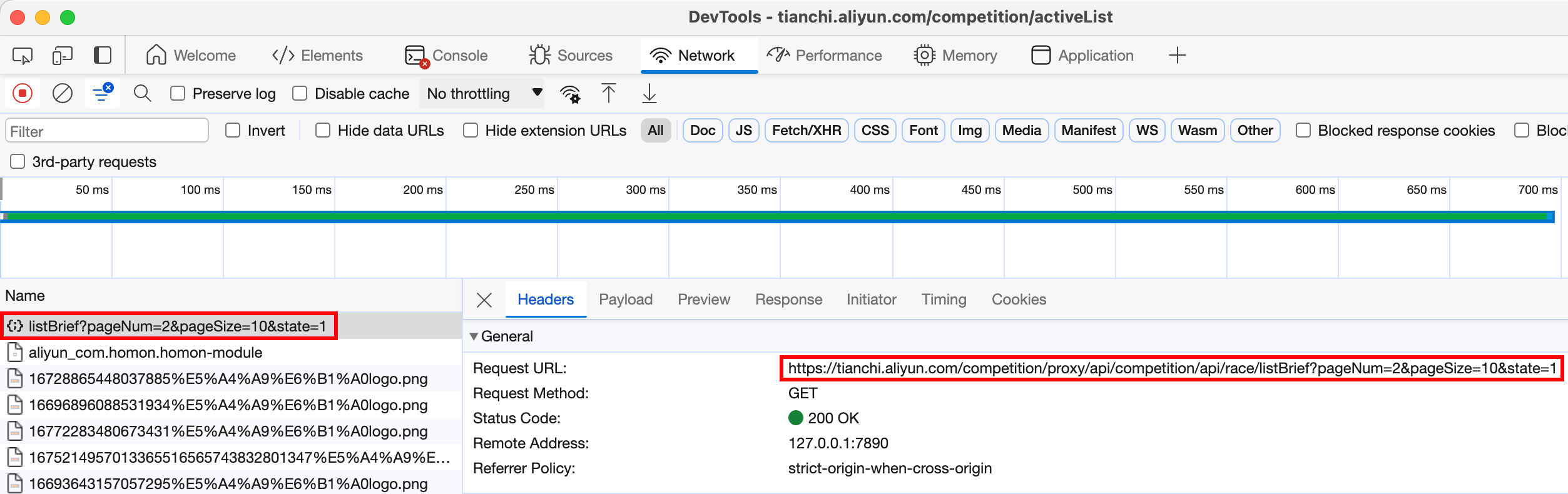
点击 page 后发现不是通过 GET Request 或者 url,而是对一个 api 进行了 GET Request,返回 JSON 数据。
pageNum=2 代表第2页,pageSize=10 代表获取10个, state=1 代表活跃竞赛
所以我们可以不用解析 HTML 了,直接对这个 api 进行 GET request,获取 JSON。
生成 spider 文件
scrapy genspider tianchi_spider "https://tianchi.aliyun.com/competition/proxy/api/competition/api/race/listBrief?pageNum=1&pageSize=10&state=1"
自动生成的 tianchi_spider.py 文件
1 2 3 4 5 6 7 8 9 10 11 import scrapyclass TianchiSpiderSpider (scrapy.Spider): name = "tianchi_spider" allowed_domains = ["tianchi.aliyun.com" ] start_urls = ["http://tianchi.aliyun.com/" ] def parse (self, response ): pass
简单修改查看是否能获取到 response
1 2 3 4 5 6 7 8 9 10 11 import scrapyclass TianchiSpiderSpider (scrapy.Spider): name = "tianchi_spider" allowed_domains = ["tianchi.aliyun.com" ] start_urls = ["http://tianchi.aliyun.com/" ] def parse (self, response ): with open ('test.html' , 'wb' ) as f: f.write(response.body)
scrapy crawl tianchi_spider -o tianchi.json
如果能够成功获取网页内容则成功。
Splash Splash 是一个 JavaScript 渲染服务,是一个带有 HTTP API 的轻量级浏览器,它可以和 Scrapy 配合实现动态渲染页面的抓取,和 selenium 的效果差不多,不过它并不是模拟人工操作浏览器。
安装 brew install --cask --appdir=/Applications docker
点开 docker 简单配置一下。
pull splash 镜像
docker pull scrapinghub/splash
在 8050 port 上 run splash 镜像
docker run -p 8050:8050 scrapinghub/splash
pip install scrapy-splash
配置 在 scrapy 生成的 setting.py 任意位置插入以下代码
1 2 3 4 5 6 7 8 9 10 11 SPLASH_URL = 'http://localhost:8050' DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware' : 723 , 'scrapy_splash.SplashMiddleware' : 725 , 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware' : 810 , } SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware' : 100 , } DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
使用 使用 SplashRequest 替换 Scrapy 的 Request 即可获取渲染后的网页。
1 2 3 4 5 from scrapy_splash import SplashRequest yield SplashRequest(url='https://tianchi.aliyun.com/competition/activeList?lang=zh-cn' , callback=self.parse_total_pages)
Demo 8: 阿里天池 活跃中的竞赛 分析 该网页采用了 ajax 技术,直接获取 html 什么都没有,这时就要使用 Splash 来获取渲染后的页面。
这个 demo 和一般的爬取不太一样,主页面和获取数据的页面不是一个。所以,首先请求的 url 应该是主页面,获取到主页面的 html 后交给 解析出所有页码的方法,然后将每个页码拼成获取数据的 url,分别交给 解析出数据的方法。共需要 3 个方法。
代码实现 setting.py 按照上一章添加
items.py
1 2 3 4 5 6 7 8 9 10 import scrapyclass TianchiItem (scrapy.Item): race_name = scrapy.Field() brief = scrapy.Field() race_type = scrapy.Field() bonus = scrapy.Field() team_num = scrapy.Field() ddl = scrapy.Field()
tianchi_spider.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import jsonimport scrapyfrom tianchi.items import TianchiItemfrom scrapy_splash import SplashRequestclass TianchiSpiderSpider (scrapy.Spider): name = "tianchi_spider" allowed_domains = ["tianchi.aliyun.com" ] def start_requests (self ): yield SplashRequest(url='https://tianchi.aliyun.com/competition/activeList?lang=zh-cn' , callback=self.parse_total_pages) def parse_total_pages (self, response ): total_pages = int (response.css('li.ant-pagination-item::attr(title)' ).getall()[-1 ]) for page in range (1 , total_pages + 1 ): page_url = f'https://tianchi.aliyun.com/competition/proxy/api/competition/api/race/listBrief?pageNum={page} &pageSize=10&state=1' yield scrapy.Request(url=page_url, callback=self.parse_page) def parse_page (self, response ): items_dict = json.loads(response.text) for item_dict in items_dict['data' ]['list' ]: item = TianchiItem() item['race_name' ] = item_dict['raceName' ] item['brief' ] = item_dict['brief' ] item['race_type' ] = item_dict['raceType' ] item['bonus' ] = f"{item_dict['currencySymbol' ]} {item_dict['bonus' ]} " item['team_num' ] = item_dict['teamNum' ] item['ddl' ] = item_dict['currentSeasonEnd' ] yield item
scrapy crawl tianchi_spider -o tianchi.json
等待渲染的时间比较长,30s 多。
可以发现页间的顺序是不固定的,这是多线程爬取导致的。
但是写入文件真的太方便了,不用自己处理多线程的冲突问题。
实现细节 回调(callback) 这个在 java 中经常用到,在 scrapy 里代表方法执行完成后不离开调用者去赋值而是回去调用另一个方法直到不需要再被回调。
json 转 python dict 用 json.loads()
逻辑顺序 scrapy 默认是多线程的,所以尽量用递归(在这里是回调)来写,不要用到顺序逻辑和循环逻辑。
选择器 主要用 response.xpath() 和 response.css()
更多见:Selectors — Scrapy 2.11.0 documentation
Anti-Crawler 本来不打算写这个的,好朋友最近要爬一个gov网站,selenium被检测出来了(“正受到自动化测试软件的控制”),这时可以用undetected_chromedriver。
1 2 import undetected_chromedriver as ucdriver = uc.Chrome()
即可。