结语:第24次CSP认证尘埃落定,210分,并不很理想,甚至没有我大一时考的高,但并不能认为自己退步了,因为近年的T2都有30%的卡常数据。T4、T5我也都写出了暴力解法,保守能过25+12分的点,但本次比赛最后一个小时一直waiting,心态崩掉了,也不知道该改哪里。学如逆水行舟,不进则退。退的不多又何尝不是一种进步呢?
202109
第1题
题目链接
题目描述
$A_1, A_2, \cdots, A_n$ 是一个由 $n$ 个自然数(即非负整数)组成的数组。在此基础上,我们用数组 $B_1 \cdots B_n$ 表示 $A$ 的前缀最大值。
如上所示,$B_i$ 定义为数组 $A$ 中前 $i$ 个数的最大值。
根据该定义易知 $A_1 = B_1$,且随着 $i$ 的增大,$B_i$ 单调不降。
此外,我们用 $sum = A_1 + A_2 + \cdots + A_n$ 表示数组 $A$ 中 $n$ 个数的总和。
现已知数组 $B$,我们想要根据 $B$ 的值来反推数组 $A$。
显然,对于给定的 $B$,$A$ 的取值可能并不唯一。
试计算,在数组 $A$ 所有可能的取值情况中,$sum$ 的最大值和最小值分别是多少?
输入格式
从标准输入读入数据。
输入的第一行包含一个正整数 $n$。
输入的第二行包含 $n$ 个用空格分隔的自然数 $B_1, B_2, \cdots, B_n$。
输出格式
输出到标准输出。
输出共两行。
第一行输出一个整数,表示 $sum$ 的最大值。
第二行输出一个整数,表示 $sum$ 的最小值。
样例1输入
1 | 6 |
样例1输出
1 | 30 |
样例1解释
数组 $A$ 的可能取值包括但不限于以下三种情况。
情况一:$A = [0, 0, 5, 5, 10, 10]$
情况二:$A = [0, 0, 5, 3, 10, 4]$
情况三:$A = [0, 0, 5, 0, 10, 0]$
其中第一种情况 $sum = 30$ 为最大值,第三种情况 $sum = 15$ 为最小值。
样例2输入
1 | 7 |
样例2输出
1 | 285 |
样例2解释
$A = [10, 20, 30, 40, 50, 60, 75]$ 是唯一可能的取值,所以 $sum$ 的最大、最小值均为 $285$。
子任务
$50%$ 的测试数据满足数组 $B$ 单调递增,即 $0 < B_1 < B_2 < \cdots < B_n < 10^{5}$;
全部的测试数据满足 $n \le 100$ 且数组 $B$ 单调不降,即 $0 \le B_1 \le B_2 \le \cdots \le B_n \le 10^{5}$。
分析
由题意,显然有$0\le A_i\le B_i$,当想要得到最大值时,只需令$A_i=B_i$,此时的数组$A_1, A_2, \cdots, A_n=B_1 \cdots B_n$,当想要得到最小值时,只需令
代码
1 | n=int(input()) |
202104
第1题
题目链接
问题描述
一幅长宽分别为 $n$ 个像素和 $m$ 个像素的灰度图像可以表示为一个 $n×m$ 大小的矩阵 $A$。
其中每个元素 $Aij$($0≤i<n$、$0≤j<m$)是一个 $[0,L)$ 范围内的整数,表示对应位置像素的灰度值。
具体来说,一个 $8$ 比特的灰度图像中每个像素的灰度范围是 $[0,128)$。
一副灰度图像的灰度统计直方图(以下简称“直方图”)可以表示为一个长度为 $L$ 的数组 $h$,其中 $h[x]$($0≤x<L$)表示该图像中灰度值为 $x$ 的像素个数。显然,$h[0]$ 到 $h[L−1]$ 的总和应等于图像中的像素总数 $n⋅m$。
已知一副图像的灰度矩阵 $A$,试计算其灰度直方图 $h[0],h[1],⋯,h[L−1]$。
输入格式
输入共 $n+1$ 行。
输入的第一行包含三个用空格分隔的正整数 $n$、$m$ 和 $L$,含义如前文所述。
第 $2$ 到第 $n+1$ 行输入矩阵 $A$。
第 $i+2$($0≤i<n$)行包含用空格分隔的 $m$ 个整数,依次为 $A_{i0},A_{i1},⋯,A_{i(m−1)}$。
输出格式
输出仅一行,包含用空格分隔的 $L$ 个整数 $h[0],h[1],⋯,h[L−1]$,表示输入图像的灰度直方图。
样例输入
1 | 4 4 16 |
样例输出
1 | 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 |
样例输入
1 | 7 11 8 |
样例输出
1 | 48 0 0 0 0 0 0 29 |
评测用例规模与约定
全部的测试数据满足 $0<n,m≤500$ 且 $4≤L≤256$。
分析
模拟题
根据题意构建各变量然后统计即可。
代码
1 | n,m,L=map(int,input().split()) |
第2题
题目链接
试题背景
顿顿在学习了数字图像处理后,想要对手上的一副灰度图像进行降噪处理。不过该图像仅在较暗区域有很多噪点,如果贸然对全图进行降噪,会在抹去噪点的同时也模糊了原有图像。因此顿顿打算先使用邻域均值来判断一个像素是否处于较暗区域,然后仅对处于较暗区域的像素进行降噪处理。
问题描述
待处理的灰度图像长宽皆为 $n$ 个像素,可以表示为一个 $n×n$ 大小的矩阵 $A$,其中每个元素是一个 $[0,L)$ 范围内的整数,表示对应位置像素的灰度值。
对于矩阵中任意一个元素 $Aij(0≤i,j<n)$,其邻域定义为附近若干元素的集合:
这里使用了一个额外的参数 $r$ 来指明 $Aij$ 附近元素的具体范围。根据定义,易知 $Neighbor(i,j,r)$ 最多有 $(2r+1)^2$ 个元素。
如果元素 $Aij$ 邻域中所有元素的平均值小于或等于一个给定的阈值 $t$,我们就认为该元素对应位置的像素处于较暗区域。
下图给出了两个例子,左侧图像的较暗区域在右侧图像中展示为黑色,其余区域展示为白色。

现给定邻域参数 $r$ 和阈值 $t$,试统计输入灰度图像中有多少像素处于较暗区域。
输入格式
输入共 $n+1$ 行。
输入的第一行包含四个用空格分隔的正整数 $n、L、r $ 和 $t$,含义如前文所述。
第二到第 $n+1$ 行输入矩阵 $A$。
第 $i+2(0≤i<n)$ 行包含用空格分隔的$n$个整数,依次为 $Ai0,Ai1,⋯,Ai(n−1)$。
输出格式
输出一个整数,表示输入灰度图像中处于较暗区域的像素总数。
样例输入
1 | 4 16 1 6 |
样例输出
1 | 7 |
样例输入
1 | 11 8 2 2 |
样例输出
1 | 83 |
评测用例规模与约定
70% 的测试数据满足 $n≤100$、$r≤10$。
全部的测试数据满足 $0<n≤600$、$0<r≤100$ 且 $2≤t<L≤256$。
分析
题目要求计算领域均值,那么首先要计算的是,其次是$|Neighbor(i,j,r)|$,对于,不难发现,如果对每一个元素进行暴力求解,将会计算大量重复区域,这样的话我们可以使用二维前缀和方法,即对于一个矩阵 $a$,我们定义一个矩阵 $psum$,使得 ,那么,要求解某一个特定的子矩阵的和,只需使用容斥原理即可。
代码
1 | n,L,r,t=map(int,input().split()) |
第3题
题目链接
试题背景
动态主机配置协议(Dynamic Host Configuration Protocol, DHCP)是一种自动为网络客户端分配 IP 地址的网络协议。当支持该协议的计算机刚刚接入网络时,它可以启动一个 DHCP 客户端程序。后者可以通过一定的网络报文交互,从 DHCP 服务器上获得 IP 地址等网络配置参数,从而能够在用户不干预的情况下,自动完成对计算机的网络设置,方便用户连接网络。DHCP 协议的工作过程如下:
- 当 DHCP 协议启动的时候,DHCP 客户端向网络中广播发送 Discover 报文,请求 IP 地址配置;
- 当 DHCP 服务器收到 Discover 报文时,DHCP 服务器根据报文中的参数选择一个尚未分配的 IP 地址,分配给该客户端。DHCP 服务器用 Offer 报文将这个信息传达给客户端;
- 客户端收集收到的 Offer 报文。由于网络中可能存在多于一个 DHCP 服务器,因此客户端可能收集到多个 Offer 报文。客户端从这些报文中选择一个,并向网络中广播 Request 报文,表示选择这个 DHCP 服务器发送的配置;
- DHCP 服务器收到 Request 报文后,首先判断该客户端是否选择本服务器分配的地址:如果不是,则在本服务器上解除对那个 IP 地址的占用;否则则再次确认分配的地址有效,并向客户端发送 Ack 报文,表示确认配置有效,Ack 报文中包括配置的有效时间。如果 DHCP 发现分配的地址无效,则返回 Nak 报文;
- 客户端收到 Ack 报文后,确认服务器分配的地址有效,即确认服务器分配的地址未被其它客户端占用,则完成网络配置,同时记录配置的有效时间,出于简化的目的,我们不考虑被占用的情况。若客户端收到 Nak 报文,则从步骤 1 重新开始;
- 客户端在到达配置的有效时间前,再次向 DHCP 服务器发送 Request 报文,表示希望延长 IP 地址的有效期。DHCP 服务器按照步骤 4 确定是否延长,客户端按照步骤 5 处理后续的配置;
在本题目中,你需要理解 DHCP 协议的工作过程,并按照题目的要求实现一个简单的 DHCP 服务器。
问题描述
报文格式
为了便于实现,我们简化地规定 DHCP 数据报文的格式如下:
1 | <发送主机> <接收主机> <报文类型> <IP 地址> <过期时刻> |
DHCP 数据报文的各个部分由空格分隔,其各个部分的定义如下:
- 发送主机:是发送报文的主机名,主机名是由小写字母、数字组成的字符串,唯一地表示了一个主机;
- 接收主机:当有特定的接收主机时,是接收报文的主机名;当没有特定的接收主机时,为一个星号(
*); - 报文类型:是三个大写字母,取值如下:
DIS:表示 Discover 报文;OFR:表示 Offer 报文;REQ:表示 Request 报文;ACK:表示 Ack 报文;NAK:表示 Nak 报文;
- IP 地址,是一个非负整数:
- 对于 Discover 报文,该部分在发送的时候为 0,在接收的时候忽略;
- 对于其它报文,为正整数,表示一个 IP 地址;
- 过期时刻,是一个非负整数:
- 对于 Offer、Ack 报文,是一个正整数,表示服务器授予客户端的 IP 地址的过期时刻;
- 对于 Discover、Request 报文,若为正整数,表示客户端期望服务器授予的过期时刻;
- 对于其它报文,该部分在发送的时候为 0,在接收的时候忽略。
例如下列都是合法的 DHCP 数据报文:
1 | a * DIS 0 0 |
服务器配置
为了 DHCP 服务器能够正确分配 IP 地址,DHCP 需要接受如下配置:
- 地址池大小 N:表示能够分配给客户端的 IP 地址的数目,且能分配的 IP 地址是 1,2,…,N;
- 默认过期时间 Tdef:表示分配给客户端的 IP 地址的默认的过期时间长度;
- 过期时间的上限和下限 Tmax、Tmin:表示分配给客户端的 IP 地址的最长过期时间长度和最短过期时间长度,客户端不能请求比这个更长或更短的过期时间;
- 本机名称 H:表示运行 DHCP 服务器的主机名。
分配策略
当客户端请求 IP 地址时,首先检查此前是否给该客户端分配过 IP 地址,且该 IP 地址在此后没有被分配给其它客户端。如果是这样的情况,则直接将 IP 地址分配给它,否则,
总是分配给它最小的尚未占用过的那个 IP 地址。如果这样的地址不存在,则分配给它最小的此时未被占用的那个 IP 地址。如果这样的地址也不存在,说明地址池已经分配完毕,因此拒绝分配地址。
实现细节
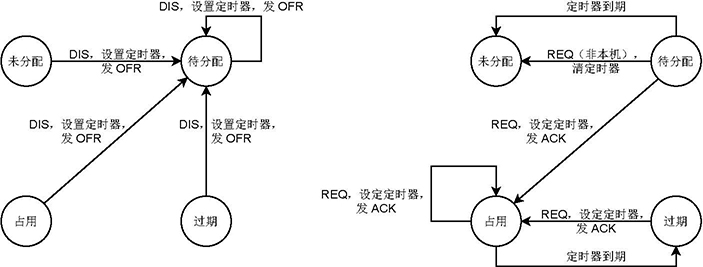
在 DHCP 启动时,首先初始化 IP 地址池,将所有地址设置状态为未分配,占用者为空,并清零过期时刻。
其中地址的状态有未分配、待分配、占用、过期四种。
处于未分配状态的 IP 地址没有占用者,而其余三种状态的 IP 地址均有一名占用者。
处于待分配和占用状态的 IP 地址拥有一个大于零的过期时刻。在到达该过期时刻时,若该地址的状态是待分配,则该地址的状态会自动变为未分配,且占用者清空,过期时刻清零;否则该地址的状态会由占用自动变为过期,且过期时刻清零。处于未分配和过期状态的 IP 地址过期时刻为零,即没有过期时刻。
对于收到的报文,设其收到的时刻为 t。处理细节如下:
- 判断接收主机是否为本机,或者为
*,若不是,则判断类型是否为 Request,若不是,则不处理; - 若类型不是 Discover、Request 之一,则不处理;
- 若接收主机为
*,但类型不是 Discover,或接收主机是本机,但类型是 Discover,则不处理。
对于 Discover 报文,按照下述方法处理:
- 检查是否有占用者为发送主机的 IP 地址:
- 若有,则选取该 IP 地址;
- 若没有,则选取最小的状态为未分配的 IP 地址;
- 若没有,则选取最小的状态为过期的 IP 地址;
- 若没有,则不处理该报文,处理结束;
- 将该 IP 地址状态设置为待分配,占用者设置为发送主机;
- 若报文中过期时刻为 0 ,则设置过期时刻为 t+Tdef;否则根据报文中的过期时刻和收到报文的时刻计算过期时间,判断是否超过上下限:若没有超过,则设置过期时刻为报文中的过期时刻;否则则根据超限情况设置为允许的最早或最晚的过期时刻;
- 向发送主机发送 Offer 报文,其中,IP 地址为选定的 IP 地址,过期时刻为所设定的过期时刻。
对于 Request 报文,按照下述方法处理:
- 检查接收主机是否为本机:
- 若不是,则找到占用者为发送主机的所有 IP 地址,对于其中状态为待分配的,将其状态设置为未分配,并清空其占用者,清零其过期时刻,处理结束;
- 检查报文中的 IP 地址是否在地址池内,且其占用者为发送主机,若不是,则向发送主机发送 Nak 报文,处理结束;
- 无论该 IP 地址的状态为何,将该 IP 地址的状态设置为占用;
- 与 Discover 报文相同的方法,设置 IP 地址的过期时刻;
- 向发送主机发送 Ack 报文。
上述处理过程中,地址池中地址的状态的变化可以概括为如下图所示的状态转移图。为了简洁,该图中没有涵盖需要回复 Nak 报文的情况。
输入格式
输入的第一行包含用空格分隔的四个正整数和一个字符串,分别是:N、Tdef、Tmax、Tmin 和 H,保证 Tmin≤Tdef≤Tmax。
输入的第二行是一个正整数 n,表示收到了 n 个报文。
输入接下来有 n 行,第 (i+2) 行有空格分隔的正整数 ti 和约定格式的报文 Pi。表示收到的第 i 个报文是在 ti 时刻收到的,报文内容是 Pi。保证 ti<ti+1。
输出格式
输出有若干行,每行是一个约定格式的报文。依次输出 DHCP 服务器发送的报文。
样例输入
1 | 4 5 10 5 dhcp |
样例输出
1 | dhcp a OFR 1 6 |
样例说明
输入第一行,分别设置了 DHCP 的相关参数,并收到了 16 个报文。
第 1 个报文和第 2 个报文是客户端 a 正常请求地址,服务器为其分配了地址 1,相应地设置了过期时刻是 7(即当前时刻 2 加上默认过期时间 5)。
第 3 个报文不符合 Discover 报文的要求,不做任何处理。
第 4 个报文 b 发送的 Discover 报文虽然有 IP 地址 3,但是按照处理规则,这个字段被忽略,因此服务器返回 Offer 报文,过期时刻是 9。
第 5 个报文中,Request 报文不符合接收主机是 DHCP 服务器本机的要求,因此不做任何处理。
第 6 个报文是 b 发送的 Request 报文,其中设置了过期时刻是 12,没有超过最长过期时间,因此返回的 Ack 报文中过期时刻也是 12。
第 7 个报文中,过期时刻 11 小于最短过期时间,因此返回的过期时刻是 12。虽然此时为 a 分配的地址 1 过期,但是由于还有状态为未分配的地址 3,因此为 c 分配地址 3。第 8 个报文同理,为 c 分配的地址过期时刻是 13。
第 9、10 两个报文中,为 d 分配了地址 4,过期时刻是 20。
第 11 个报文中,a 请求重新获取此前为其分配的地址 1,虽然为其分配的地址过期,但是由于尚未分配给其它客户端,因此 DHCP 服务器可以直接为其重新分配该地址,并重新设置过期时刻为 20。
第 12 个报文中,c 请求延长其地址的过期时刻为 20。DHCP 正常向其回复 Ack 报文。
第 13、14 个报文中,e 试图请求地址。此时地址池中已经没有处于“未分配”状态的地址了,但是有此前分配给 b 的地址 2 的状态是“过期”,因此把该地址重新分配给 e。
第 15 个报文中,b 试图重新获取此前为其分配的地址 2,但是此时该地址已经被分配给 e,因此返回 Nak 报文。
第 16 个报文中,b 试图重新请求分配一个 IP 地址,但是此时地址池中已经没有可用的地址了,因此忽略该请求。
样例输入
1 | 4 70 100 50 dhcp |
样例输出
1 | dhcp b OFR 1 70 |
样例说明
在本样例中,DHCP 服务器一共收到了 6 个报文,处理情况如下:
第 1 个报文不是 DHCP 服务器需要处理的报文,因此不回复任何报文。
第 2 个报文中,b 请求分配 IP 地址,因此 DHCP 服务器将地址 1 分配给 b,此时,地址 1 进入待分配状态,DHCP 服务器向 b 发送 Offer 报文。
第 3 个报文中,b 发送的 REQ 报文是发给非本服务器的,因此需要将地址池中所有拥有者是 b 的待分配状态的地址修改为未分配。
第 4 个报文中,c 请求分配 IP 地址。由于地址 1 此时是未分配状态,因此将该地址分配给它,向它发送 Offer 报文,地址 1 进入待分配状态。
第 5、6 个报文中,d 请求分配 IP 地址。注意到在收到第 5 个报文时,已经是时刻 70,地址 1 的过期时刻已到,它的状态已经被修改为了未分配,因此 DHCP 服务器仍然将地址 1 分配给 d。
评测用例规模与约定
对于 20% 的数据,有 N≤200,且 n≤N,且输入仅含 Discover 报文,且 t<Tmin;
对于 50% 的数据,有 N≤200,且 n≤N,且 t<Tmin,且报文的接收主机或为本机,或为 *;
对于 70% 的数据,有 N≤1000,且 n≤N,且报文的接收主机或为本机,或为 *;
对于 100% 的数据,有 N≤10000,且 n≤10000,主机名的长度不超过 20,且 t,Tmin,Tdefault,Tmax≤109,输入的报文格式符合题目要求,且数字不超过 109。
问题分析
模拟就是用计算机来模拟题目中要求的操作。
大模拟,也就是复杂模拟题,是CSP中T3的的固定题型。
代码对应的要求已经注释在了旁边,故这里略。
代码
1 |
|
第4题
题目链接
问题描述
X 校最近打算美化一下校园环境。前段时间因为修地铁,X 校大门外种的行道树全部都被移走了。现在 X 校打算重新再种一些树,为校园增添一抹绿意。
X 校大门外的道路是东西走向的,我们可以将其看成一条数轴。在这条数轴上有 n 个障碍物,例如电线杆之类的。虽然障碍物会影响树的生长,但是障碍物不一定能被随便移走,所以 X 校规定在障碍物的位置上不能种树。n 个障碍物的坐标都是整数;如果规定向东为正方向,则 n 个障碍物的坐标按照从西到东的顺序分别为 a1,a2,⋯,an。X 校打算在 [a1,an] 之间种一些树,使得这些树看起来比较美观。
X 校希望,在一定范围内,树应该是等间隔的。更具体地说,如果把 [a1,an) 划分成一些区间 [ap1,ap2),⋯,[apm−1,apm)(1=p1<p2<⋯<pm=n),那么每个区间 [api,api+1) 内需要至少种一棵树,且该区间内种的树的坐标连同区间端点 api,api+1 应该构成一个等差数列。不同区间的公差,也就是树的间隔可以不相同。
例如,如果障碍物位于 0,2,6 这三处,那么我们可以选择在 [0,2) 和 [2,6) 分别种树,也可以选择在 [0,6) 等间隔种树。如果是分别在 [0,2) 和 [2,6) 种树,由于每个区间内至少要种一棵树,坐标 1 上必须种树;而 [2,6) 上的树可以按照 1 的间隔种下,也可以按照 2 的间隔种下。下图表示了这两种美观的种树方案,其中橙色的圆表示障碍物,绿色的圆表示需要在这个位置种树,箭头上的数字表示种下这棵树时对应的间隔为多少。
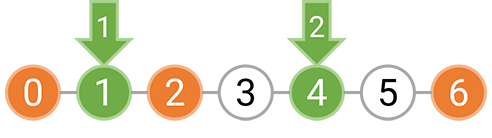
对区间 [0,2) 和 [2,6) 分别以 1 和 2 的间隔种树是美观的
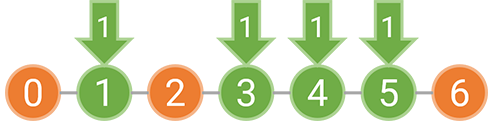
对区间 [0,2) 和 [2,6) 分别以 1 的间隔种树也是美观的
而如果选择在 [0,6) 区间等间隔种树,我们只能以 3 的间隔种树,因为无论是选择间隔 1 或者间隔 2,都需要在坐标 2 上种树,而这个位置已经有障碍物了。下图分别表示了间隔为 3,2,1 时的种树情况,红色箭头表示不能在这里种树。
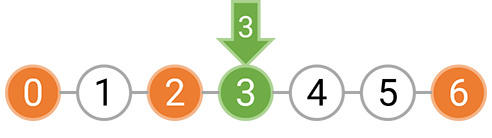
对区间 [0,6) 以 3 的间隔种树是美观的
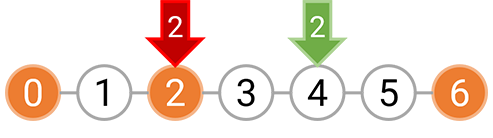
对区间 [0,6) 以 2 的间隔种树是不美观的
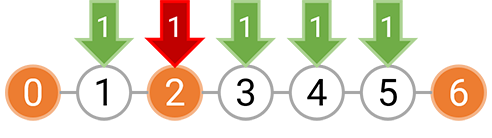
对区间 [0,6) 以 1 的间隔种树也是不美观的
一般地,给定一个区间 $[al,ar)$,对于树的坐标的集合 $T⊂(al,ar)(T⊂Z)$,归纳定义 $T$ 在 $[al,ar)$ 上是美观的:
- 如果 $T≠∅$,$T∩{al,al+1,⋯,ar}=∅$,并且存在一个公差 $d≥1$,使得 $T∪{al,ar}$ 中的元素按照从小到大的顺序排序后,可以构成一个公差为 $d$ 的等差数列(显然,这个等差数列的首项为 $al$,末项为 $ar$),则 $T$ 在 $[al,ar)$ 上是美观的;
- 如果 $T∩{al,al+1,⋯,ar}=∅$,并且存在一个下标 $m(l<m<r)$,使得 $T∩(al,am)$ 在 $[al,am)$ 上是美观的,且 $T∩(am,ar)$ 在 $[am,ar)$ 上是美观的,则 $T$ 在 $[al,ar)$ 上是美观的。
根据这一定义,空集在任意区间上都不是美观的;另外,如果存在下标 $i$ 使得 $ai∈T$,那么 $T$ 一定不是美观的。
我们称两种种树的方案是本质不同的,当且仅当两种方案中,种树的坐标集合不同。请帮助 X 校对 $[a1,an)$ 求出所有本质不同的美观的种树方案。当然,由于方案可能很多,你只需要输出总方案数对 $10^9+7$ 取模的结果。
输入格式
输入的第一行包含一个正整数 $n$,表示障碍物的数量。
输入的第二行包括 $n$ 个非负整数 $a1,⋯,an$,表示每个障碍物的坐标。
保证对 $i=1,2,⋯,n−1$,$ai<ai+1$。
输出格式
输出一个非负整数,表示本质不同的美观的种树方案的数量对 $10^9+7$ 取模的结果。
样例输入
1 | 3 |
样例输出
1 | 3 |
样例说明
这组样例即为题面描述中提到的那组。
样例输入
1 | 11 |
样例输出
1 | 256507 |
样例输入
1 | 333 |
样例输出
1 | 7094396 |
评测用例规模与约定
对于 10% 的数据,保证 n=2;
对于 30% 的数据,保证 n≤10;
对于 60% 的数据,保证 n≤100,ai≤1000;
对于 100% 的数据,保证 2≤n≤1000,0≤ai≤100,000,且至少存在一种美观的种树方案。
问题分析
动态规划+打表
设$dp[i]$为到第i个障碍物之间的方案总数,那么有状态转移方程
其中$calc(j,i)$为第$j$个障碍物到第$i$个障碍物的方案总数。
为了得出优化的calc函数进行如下分析:
第j个障碍物到第i个障碍物的间隔必须为obstacles[i]-obstacles[j]的因子,否则树不是等间隔的,挑选撞不上障碍物的因子作为种树方案。
若从j从i-1开始倒着枚举,开始时i-1和i之间没有障碍物,即obstacles[i]-obstacles[i-1]的所有因子都是种树方案,将这些因子设为不可再用(false),当j=i-2时,对因子进行筛选时不可使用false的因子,因为按这些间隔排序一定会撞到原先作为左端点的障碍物。
所以我们可以从i-1到1遍历j,如果obstacles[i]-obstacles[j]的因子可使用就数量+1并标记为false,否则啥也不干。
注意当i增长时要重置因子可用集合flag为true。
因为我们需要频繁地获取某区间长度的因子,所以可以用筛选法进行预处理,即将因子打个表
这个表可以从1打到最大长度AMAX,也可以进行时间复杂度的优化,因为
- 种树间隔不会超过最大障碍物距离的一半
- 种树的区间不会超过最大障碍物距离
注:最大障碍物距离只是我形象的说法,其实比真实的最大障碍物距离大,因为坐标0不一定有障碍物。
代码
1 |
|
知识
宏定义可以定义一个空的宏,如
#define DEBUG,这种宏只能被用来判断是否被定义,常用于DEBUG时运行一些不想在RELEASE运行的语句使用方法
1
2
3
4
5
6
7
定义了DEBUG时要做的
[
没定义DEBUG时要做的
]sizeof其实是个关键字,一直认为它是函数的原因在于它经常加括号使用以区分操作对象举个例子
1
2
3
4int* p=new int[2]{0,0};
printf("%zd\n",sizeof p);
printf("%zd\n",sizeof p+1);
printf("%zd\n",sizeof (p+1));输出
1
2
38
9
8注:%zd是sizeof的返回类型unsigned int的输出控制符
202012
期末预测之安全指数
题目链接
题目背景
考虑到安全指数是一个较大范围内的整数、小菜很可能搞不清楚自己是否真的安全,顿顿决定设置一个阈值 $θ$,以便将安全指数 $y$ 转化为一个具体的预测结果——“会挂科”或“不会挂科”。
因为安全指数越高表明小菜同学挂科的可能性越低,所以当 $y≥θ$ 时,顿顿会预测小菜这学期很安全、不会挂科;反之若 $y<θ$,顿顿就会劝诫小菜:“你期末要挂科了,勿谓言之不预也。”
那么这个阈值该如何设定呢?顿顿准备从过往中寻找答案。
题目描述
具体来说,顿顿评估了 $m$ 位同学上学期的安全指数,其中第 $i$($1≤i≤m$)位同学的安全指数为 $y_i$,是一个 $[0,108]$ 范围内的整数;同时,该同学上学期的挂科情况记作 $resulti∈0,1$,其中 $0$ 表示挂科、$1$ 表示未挂科。
相应地,顿顿用 表示根据阈值 $θ$ 将安全指数 $y$ 转化为的具体预测结果。
如果 与 $result_j$ 相同,则说明阈值为 $θ$ 时顿顿对第 $j$ 位同学是否挂科预测正确;不同则说明预测错误。
最后,顿顿设计了如下公式来计算最佳阈值 $\theta^*$:
该公式亦可等价地表述为如下规则:
- 最佳阈值仅在 ${ y_i }$ 中选取,即与某位同学的安全指数相同;
- 按照该阈值对这 $m$ 位同学上学期的挂科情况进行预测,预测正确的次数最多(即准确率最高);
- 多个阈值均可以达到最高准确率时,选取其中最大的。
输入格式
从标准输入读入数据。
输入的第一行包含一个正整数 $m$。
接下来输入 $m$ 行,其中第 $i$($1≤i≤m$)行包括用空格分隔的两个整数 $y_i$ 和 $result_i$,含义如上文所述。
输出格式
输出到标准输出。
输出一个整数,表示最佳阈值 $\theta^∗$。
样例1输入
1 | 6 |
样例1输出
1 | 3 |
样例1解释
按照规则一,最佳阈值的选取范围为 $0,1,3,5,7$。
$θ=0$ 时,预测正确次数为 $4$;
$θ=1$ 时,预测正确次数为 $5$;
$θ=3$ 时,预测正确次数为 $5$;
$θ=5$ 时,预测正确次数为 $4$;
$θ=7$ 时,预测正确次数为 $3$。
阈值选取为 $1$ 或 $3$ 时,预测准确率最高;
所以按照规则二,最佳阈值的选取范围缩小为 $1$,$3$。
依规则三,$\theta^* = \max { 1, 3 } = 3$。
样例2输入
1 | 8 |
样例2输出
1 | 100000000 |
子任务
$70\%$ 的测试数据保证 $m≤200$;
全部的测试数据保证 $2≤m≤105$。
问题分析
模拟一个加权公式
代码
1 | n=int(input()) |
期末预测之最佳阈值
题目链接
问题分析
前缀和、后缀和
根据题意和用例规模可以知道很容易写出70分的$O(n^2)$解,其主要优化点在于:
- 怎样跳过的相同安全指数$y_i$
- 怎样在遍历时确定选定阈值对应的预测正确次数
不难发现,第一份代码中对于优化点1将和对比,如果相同则跳过,对于优化点2没做处理,暴力地使用了遍历,在$O(n)$的时间内获取到了预测正确次数,很容易知道在阈值变为下一个的时候,前后两段的预测正确者重合度很高,对于这种情况一般可以使用前/后缀和+容斥原理(本题是一维列表,未用到容斥原理)进行优化。
第二份代码对于优化点1建立了一个“相等值的下标列表”,对于相等的几个安全指数采用第一个安全指数的下标,对于优化点2,使用前缀和及后缀和在$O(1)$的时间内获取到了预测正确次数。
代码
$O(n^2)$的70分解
1 | m=int(input()) |
$O(n)$的100分解
1 | m=int(input()) |
202006
线性分类器
题目链接
分析
简单模拟
按类别将输入分好类
然后使用judgeX函数分别判断A类B类点代入后是否都具有相同的符号。
这里用到了一点高中数学的知识,在同一侧的点代入函数后都应该有相同的符号,至于在某一侧是否有固定的符号我记不清了,所以我先获取了第一个点代入后的符号,然后看后面的点是否都跟这个符号相等,其实这两个符号应该是正负相反的,但是数据集好像没有考这里,有点混乱,做出来就行。
代码
1 | n,m=map(int,input().split()) |
稀疏向量
题目链接
分析
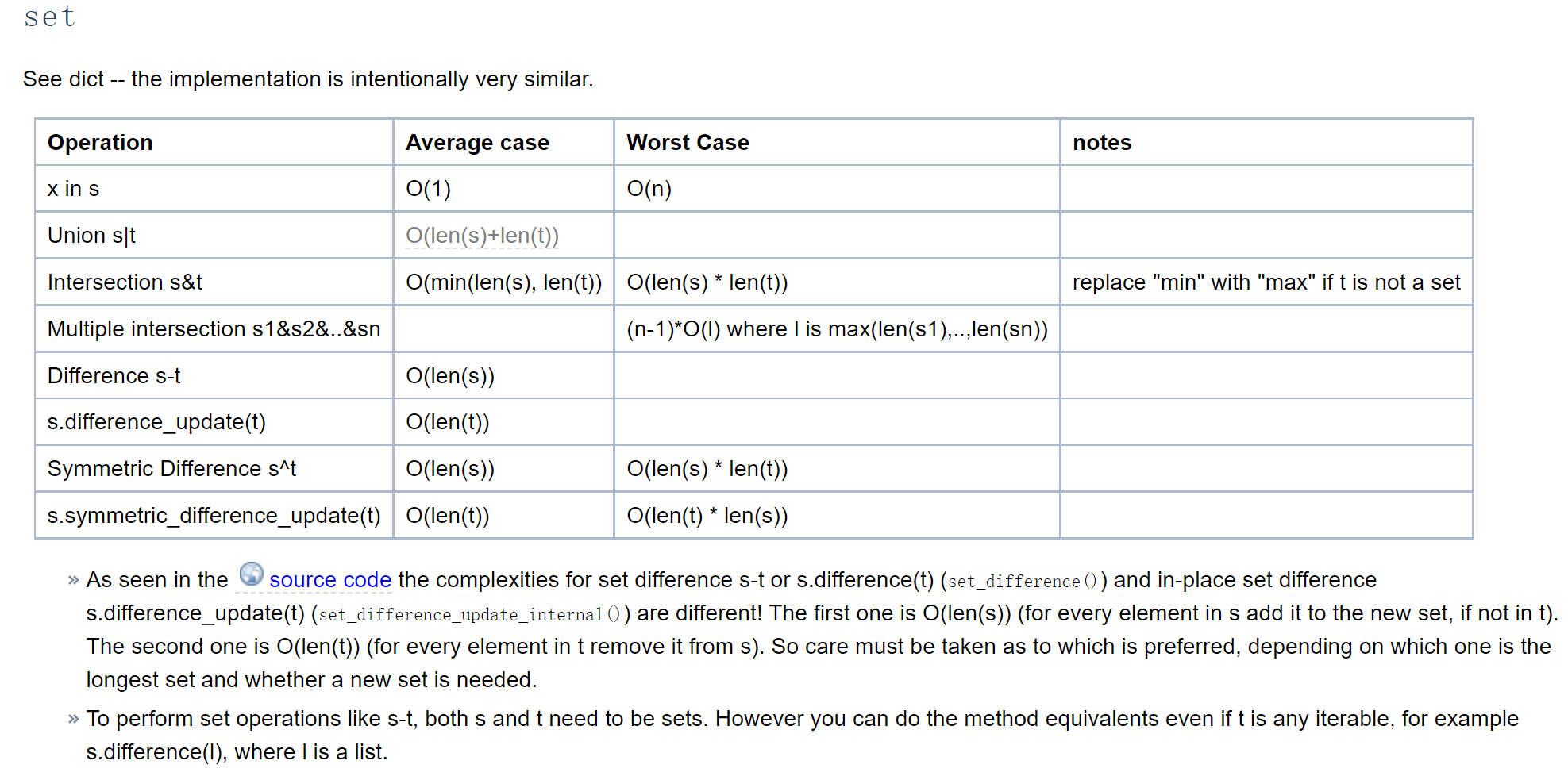
基本思路是用映射把稀疏向量保存起来,只有两个向量的键上都有值时才求他们值的乘积,其余情况的乘积都是0,那么可以使用集合求键的交集来实现找相同元素,解法一基于此思路,但这样要考虑到求交集所需的时间,据python wiki,Intersection s&t的平均时间复杂度为O(min(len(s), len(t)),而解法二的k in d的平均时间复杂度为O(1),所以我们可以把“求交”替换为“属于”。

代码
90分解
1 | n,a,b=map(int,input().split()) |
100分解
1 | n,a,b=map(int,input().split()) |
201709
通信网络
题目链接
分析
DFS
一道比较简单的DFS,用C++11风格写的
首先要有
- 一个二维long long向量,用来表示图
- 一个二维bool向量,用来表示i知道j
- 一个一维bool向量,用来表示“访问过”,这里本应是二维,为了降低空间复杂度把它设计成了一维,每次将它重新初始化为“未访问过”(false)
接着设计一个DFS函数
- 对于进入到函数中的点对,标记为“访问过”(true)
- 对于进入到函数中的点对,将他们标记为互相知道
- 对于点对中第一个点的每个出度点,若没被访问过,将他们扔入dfs函数
最后在主函数中
- 将输入构造为邻接表(由稀疏向量有感:邻接表其实就是稀疏的邻接矩阵)
- 将每一个点和它自己扔入dfs函数(每个点肯定知道自己)
- 最后按行遍历“二维知道向量”,如果某行知道所有点(true的数量等于点的数量),把结果自增1
至于为什么这道题不取消visit标记,我不知道。
代码
1 |
|
JSON查询
题目链接
分析
震惊我一整年的题,python花活太多了
一个是这个输入正好符合python中dict的样式,可以直接用exec将字符串作为语句执行
第二是可以直接导入json库,用本身的loads函数创建半结构数据
代码
100分法一
1 | n,m=map(int,input().split()) |
100分法二
1 | import json |